Implementation and Performance Evaluation of Bit Manipulation Extension on CVA6 RISC-V
Published in ACM, New York, NY, USA, May, 2023
Authors: MUHAMMAD IJAZ, 10xEngineers, Pakistan, FATIMA SALEEM, 10xEngineers, Pakistan, UMER SHAHID, 10xEngineers, Pakistan and Department of Electrical Engineering, University of Engineering and Technology, Pakistan, SAAD WAHEED, 10xEngineers, Pakistan, JEAN-ROCH COULON,Thales Group, France
An embedded system requires two conflicting attributes, low power and high performance. Embedded controllers and Internet of Things (IoT) applications are seeing a paradigm shift from using x86 or ARMv8 to the widely accepted RISC-V architecture. Bit manipulation Instructions improve the speed of bit manipulation by providing better system performance due to its improved code density, low power consumption, and improved runtime efficiency. RISC-V base Instruction Set Architecture (ISA) doesn’t support bit manipulation instructions. However, due to RISC-V architecture’s modularized instruction extension support, processor designers can add bit manipulation instructions to support low-power embedded applications. In this paper, we have implemented the bit manipulation extension (B-extension) of RISC-V on OpenHW’s application class SoC CVA6. We have synthesized the design for both the Kintex-7 FPGA board using Xilinx Vivado ISE 2018.2 and the TSMC 65 nm cell library. We have performed quantitative analysis on size and power improvement with the help of FPGA and ASIC synthesis data. The performance and code size reduction capacity is presented by showing the performance results of Dhrystone standard benchmarks against the standard CVA6 ISA (IMAFDC or IMAFC) for both RV64 and RV32 configurations. The result shows 4% improvement in dynamic power usage for RV64, 12.5% improvement in code size while building Linux image for RV64IMAFDCB at the cost of 4% increase in LUTs for FPGA implementation and 3% increase in gate count for ASIC implementation. We have seen 18% speed-up and 4% code size reduction for the Dhrystone benchmark.
Introduction
RISC-V is an open-source ISA [9] whose base extension supports word-sized, and half word sized operations. The RISC-V Bitmanip extension (short for “Bit Manipulation”) [7] is a standard extension of the RISC-V instruction set architecture that adds instructions for bit-level operations such as bit counting, bit field extraction and insertion, and bitwise logical and arithmetic operations. The Bitmanip extension provides a set of instructions for manipulating individual bits or groups of bits within a register. These operations are often used in cryptography, data compression, and other performance-critical applications.
All Bitmanip instructions are listed in Table 1. Whereas some key instructions provided by the Bitmanip extension include:
- Bit counting instructions: These instructions count the number of 1s in a register, or in a subset of the register’s bits.
- Bit field extraction and insertion instructions: These instructions extract or insert a subset of bits from or into a register.
- Bitwise logical and arithmetic instructions: These instructions perform logical and arithmetic operations on the bits of a register.

The Bitmanip extension can be implemented in hardware or software, depending on the design of the processor. A few application class cores, like Rocket [1] and Shakti Class C [4] [6] have implemented the Bitmanip extension resulting in some performance gains. The Bitmanip extension is designed to be scalable, allowing for implementations with varying levels of support for different instructions. To date, its frozen specifications include four classes of instructions which are the address generation instructions (zba), basic bit-manipulation instructions (zbb), carry-less multiplication instructions (zbc), and single bit instructions (zbs). All the RISC-V bit manipulation instructions use general-purpose registers and require no new instruction format. As shown in Table-2, each new Bitmanip instruction replaces at-least two or three RISC-V base ISA instructions resulting in increased performance with reduced code size and improved energy efficiency [2].
CVA6 [11], also known as Ariane Core, is OpenHW’s application class processor. It is one of the most recognized open-source RISC-V application class cores [3] and was developed on PULP open-source platform. It is a six-stage pipeline core that implements RV64IMAFDC architecture with three privilege levels. It has its Builtroot [8] image available at CVA6-SDK repo [5] for the purpose of cross-compiling embedded Linux systems. In this paper, we have implemented bit manipulation instructions support for CVA6 and evaluated its performance by running Linux image

and Dhrystone v2.0 benchmark codes [10]. The results are compared against standard implementation for RV64 and RV32.
CVA6 BIT Manipulation Support
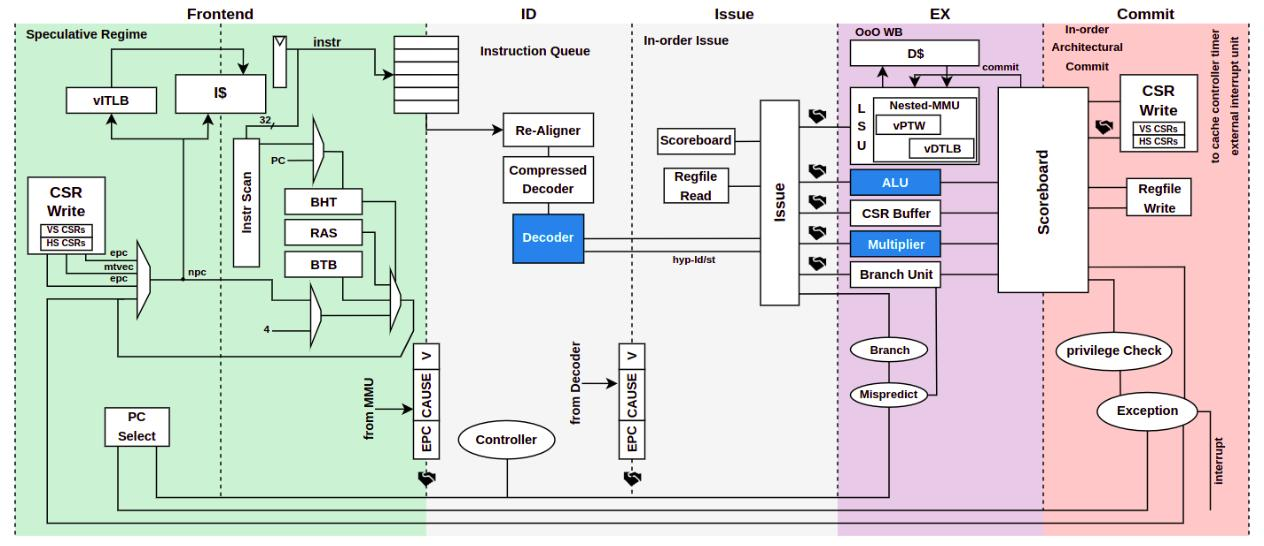
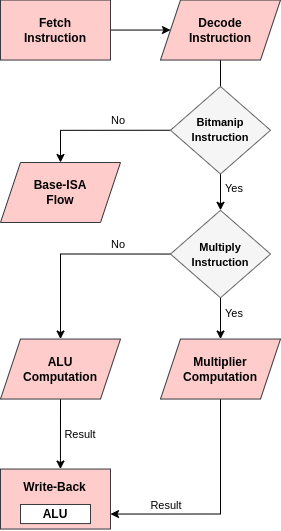
The microarchitectural changes to CVA6 for supporting hardware Bitmanip instructions is illustrated in Fig 1. To add support for these extensions, we have extended/modified the Decoder, ALU, and Multiplier modules of the CVA6 (highlighted in the figure). The major changes have been done to the Decoder module which includes adding the RISC-V Bitmanip opcodes and selecting the appropriate CVA6 Functional Unit, Multiplier or the ALU, depending upon the type of bit manipulation instruction. So, for instance, the sh1add – shift by 1 add instruction’s functionality consists of a shift and addition and as such is executed in the ALU. On the other hand the clmul – carry-less multiplication instruction performs a carry-less multiplication and so it is executed in the Multiplier unit. This also illustrates that both the ALU and the multiplier units have to be modified to support Bitmanip instructions. This flow is illustrated in Fig 2.
Results Analysis
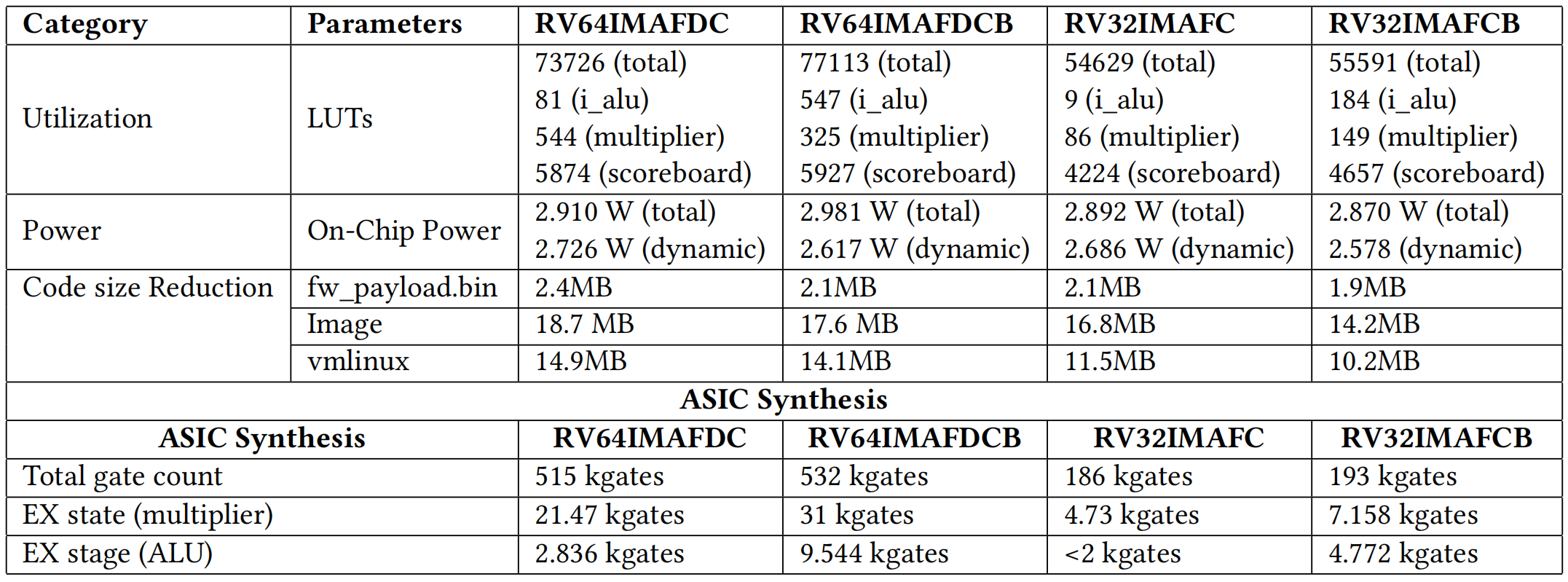
In this section, the ASIC and FPGA implementation results are compared between the standard CVA6 core and the modified core with Bitmanip extensions. Dhrystone benchmark was compiled with RISC-V GCC version 12.2.0 and run on a Linux-booted CVA6 core on a Kintex-7 FPGA board. The FPGA synthesis was done using Xilinx Vivado 2018.1. The ASIC synthesis was done using the TMSC 65 nm PDK and its gate count was compared against the standard implementation. The complete results of the ASIC and FPGA implementations are given in Table 3. The results of Dhrystone benchmark are listed in Table 4.
ASIC Synthesis
The ASIC Synthesis was done by Thales Group, France. The same design and physical parameters are used for the ASIC synthesis of the standard CVA6 and CVA6 with Bitmanip instructions. From the synthesis results we see that the overall gate count increased by 3% (from 515 Kgates to 532 Kgates)after integrating Bitmanip extension support in the standard RV64 CVA6. For RV32, the overall gate count increased by 4% (from 186 Kgates to 193 Kgates). This increase can be explained by the fact that new logic was added to the decoder, multiplier unit, and ALU units. The multiplier unit’s gate count increased by 44% and the ALU gate count increased by 200% whereas the gate count increase for the decoder was negligible. The complete results are shown in Table 3.
FPGA Synthesis
For FPGA synthesis the Kintex-7 FPGA board was used. This synthesis was done by the 10xEngineers group. As expected, the resource utilization increased by 4% in RV64 and 5% in RV32. The complete results of the FPGA resource utilization is shown in Table 3. This increase in utilization was the cost paid for the performance gain achieved by the efficiency of the Bitmanip extension. After integrating Bitmanip instruction support, the dynamic power consumption was reduced by 4% due to the reduced code size.
Linux Image
The Linux image was built using CVA6-sdk and was run on the FPGA board with and without Bitmanip versions of the processor. The Linux image size was reduced by 1 MB and the instruction count was reduced by around 230 instructions for RV64. Not only does the reduced size affect the overall OS, but having the Bitmanip version of the processor results in several additional advantages, which are listed below:
- Improved performance: The Bitmanip extension adds new instructions to the RISC-V instruction set that can be used to perform bitwise operations more efficiently. This can lead to improved performance for applications that make heavy use of bitwise operations, such as encryption algorithms or image processing software.
- Future-proofing: Building a Linux image with Bitmanip extension support ensures that the system will be able to take advantage of these new instructions and remain compatible with future RISC-V processors.
- Enhanced security: The Bitmanip extension includes instructions that can be used to perform cryptographic operations, such as AES encryption and decryption. Building a Linux image with Bitmanip extension support can enable the use of these instructions, which can help to enhance the security of the system.
- Simplified software development: By providing a standard set of instructions for performing bitwise operations, the Bitmanip extension can simplify software development and make it easier to write efficient code. This can result in faster development times and more reliable software.
- Improved energy efficiency: The bitmanip extension can enable more efficient implementation of certain algorithms, which can reduce the power consumption of the system. This can be helpful for battery-powered devices or other systems with strict power constraints.
In summary, building a Linux image with Bitmanip extension support can provide several benefits, including improved performance, future-proofing, enhanced security, simplified software development, and improved energy efficiency.
Dhrystone benchmark results
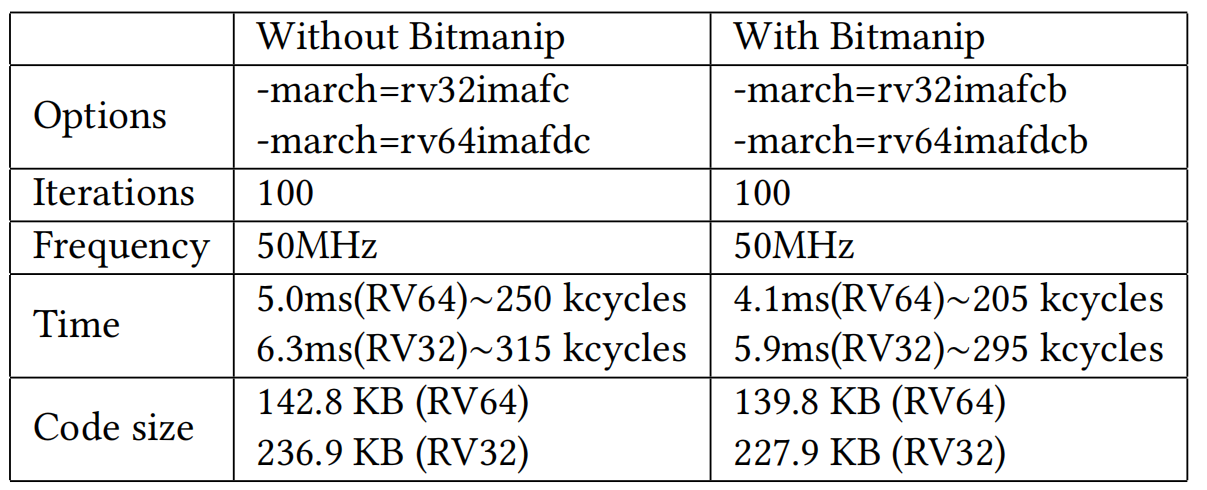
Dhrystone [10] is a popular synthetic benchmark program that has been widely used to evaluate the performance of processors. It was originally developed by Reinhold P. Weicker in 1984 as a successor to an earlier benchmark called Whetstone. The benchmark is designed to measure the performance of a processor in terms of how many Dhrystone instructions it can execute in a second. The Dhrystone benchmark program consists of a set of tasks that include integer arithmetic, conditional and unconditional branching, and memory access operations. One of the advantages of the Dhrystone benchmark is that it is a standardized test that can be used to compare the performance of different processors and computer architectures. Dhrystone v2.0 was compiled with RISC-V GCC v12.2.0 without (-march=RV64IMAFDC and RV32IMAFC) and with (-march=RV64IMAFDC_zba_zbb_zbc and RV32IMAFC_zba_zbb_zbc) Bitmanip extension flag enabled. The compiled executable was run under the Linux-booted CVA6 on the FPGA board. Overall 18% speed-up and 4% code-size reduction was seen for the Dhrystone benchmark. The results are shown in Table 4.
Conclusion
In this paper we have shown the implementation of the Bitmanip extension support in application class RISC-V processor (CVA6) and evaluated the ASIC 294 and FPGA synthesis data, Linux code size and Dhrystone benchmark results. The data show that a standard CVA6 (RV64IMAFDC or RV32IMAFC) implemented on a FPGA versus a CVA6 with the Bitmanip extensions (RV64IMAFDCB or RV32IMAFCB) results in a 4% improvement in dynamic power for RV64 (5% improvement for RV32) , 12.5% improvement in code-size for RV64 Linux image (9% improvement for RV32) at a cost of 4% increase in LUTs for an FPGA implementation (3% increase in gate count for ASIC implementation.) We have also seen 18% speed-up and 4% code size reduction in the results of the Dhrystone benchmark.
References
[1] Krste Asanović, Rimas Avizienis, Jonathan Bachrach, Scott Beamer, David Biancolin, Christopher Celio, Henry Cook, Daniel Dabbelt, John Hauser, Adam Izraelevitz, Sagar Karandikar, Ben Keller, Donggyu Kim, John Koenig, Yunsup Lee, Eric Love, Martin Maas, Albert Magyar, Howard Mao, Miquel Moreto, Albert Ou, David A. Patterson, Brian Richards, Colin Schmidt, Stephen Twigg, Huy Vo, and Andrew Waterman. 2016. The Rocket Chip Generator. Technical Report UCB/EECS-2016-17. EECS Department, University of California, Berkeley. http://www2.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-17.html
[2] P S Babu, Snehashri Sivaraman, Deepa N Sarma, and Tripti S Warrier. 2021. Evaluation of Bit Manipulation Instructions in Optimization of Size and Speed in RISC-V. In 2021 34th International Conference on VLSI Design and 2021 20th International Conference on Embedded Systems (VLSID). 54–59. https://doi.org/10.1109/VLSID518a30.2021.00014
[3] Alexander Dörflinger, Mark Albers, Benedikt Kleinbeck, Yejun Guan, Harald Michalik, Raphael Klink, Christopher Blochwitz, Anouar Nechi, and Mladen Berekovic. 2021. A comparative survey of open-source application-class RISC-V processor implementations. Proceedings of the 18th ACM International Conference on Computing Frontiers (2021). https://doi.org/10.1145/3457388.3458657
[4] Neel Gala, Arjun Menon, Rahul Bodduna, Gs Madhusudan, and Kamakoti Veezhinathan. 2016. SHAKTI Processors: An Open-Source Hardware Initiative. 7–8. https://doi.org/10.1109/VLSID.2016.130
[5] OpenHW group. 2019. CVA6-SDK. https://github.com/openhwgroup/cva6-sdk Accessed: 2023-03-06.
[6] Vineet Jain, Abhishek Sharma, and Eduardo Augusto Bezerra. 2020. Implementation and extension of BIT manipulation instruction on RISC-V architecture using FPGA. 2020 IEEE 9th International Conference on Communication Systems and Network Technologies (CSNT) (2020). https://doi.org/10.1109/csnt48778.2020.9115759
[7] Bastian Koppelmann, Peer Adelt, Wolfgang Mueller, and Christoph Scheytt. 2019. RISC-V Extensions for Bit Manipulation Instructions. In 2019 29th International Symposium on Power and Timing Modeling, Optimization and Simulation (PATMOS). 41–48. https://doi.org/10.1109/PATMOS.2019.8862170
[8] Buildroot making embedded Linux Easy. 2019. Buildroot making embedded Linux Easy. https://buildroot.org/ Accessed: 2023-03-06
[9] Andrew Waterman, Yunsup Lee, David A Patterson, and Krste Asanovic. 2011. The risc-v instruction set manual, volume i: Base user-level isa.EECS Department, UC Berkeley, Tech. Rep. UCB/EECS-2011-62 116 (2011).
[10] Reinhold P. Weicker. 1984. Dhrystone. Commun. ACM 27, 10 (1984), 1013–1030. https://doi.org/10.1145/358274.358283
[11] Zaruba and L. Benini. 2019. The Cost of Application-Class Processing: Energy and Performance Analysis of a Linux-Ready 1.7-GHz 64-Bit RISC-V Core in 22-nm FDSOI Technology. IEEE Transactions on Very Large Scale Integration (VLSI) Systems 27, 11 (Nov 2019), 2629–2640. https://doi.org/10.1109/TVLSI.2019.2926114