Making ARA Vector Processor RISC-V Vector Extension (RVV) 1.0 Compatible
Author: Nouman Akbar, 10xEngineers, Pakistan
Introduction
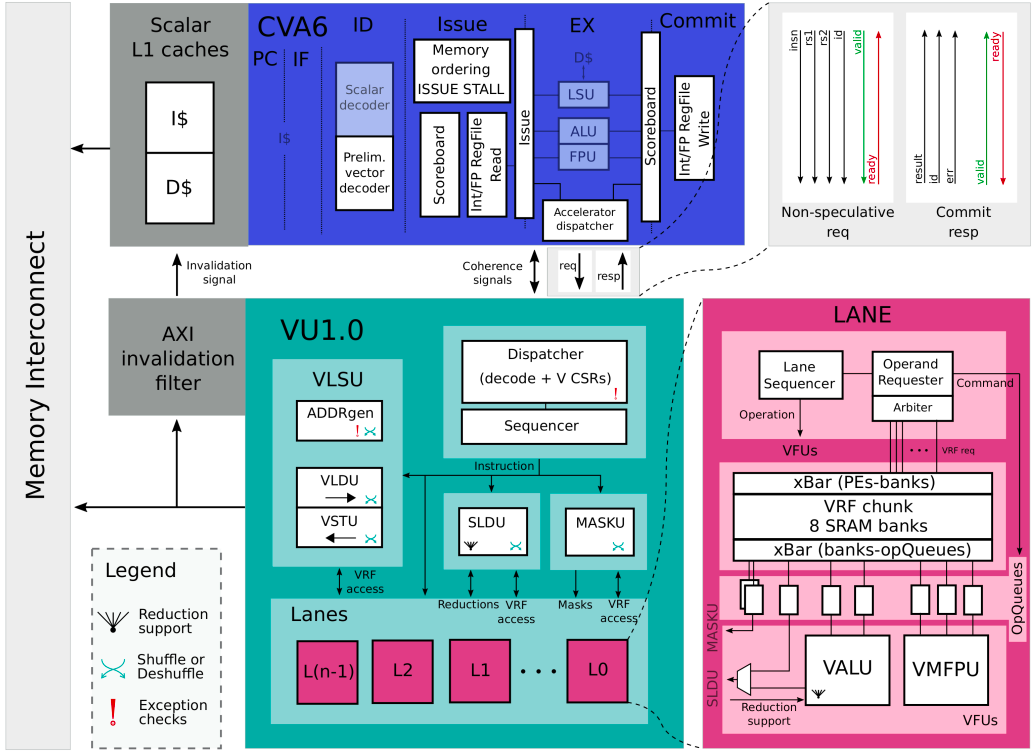
The RISC-V Vector Extension (RVV) has undergone significant revisions since its initial release in 2015, with version 1.0 ratified and frozen after 6 years in November 2021. Its ratification is an important milestone as it provides an open-source and standardized extension for hardware and software development. It served as the openly available alternative to the proprietary ISA’s and thus enabled open-source implementations of vector processors. One of those is the ARA, which is an open-source, scalable, 64-bit vector processor hosted by the pulp platform. It is currently configured as the co-processor of CVA6 as shown in figure 1. ARA runs at more than 1 GHz in the typical corner. Initially, it was based on the version 0.5 draft of RISC-V Vector Extension (RVV) and gradually updated to RVV version 0.10. It required updates to ensure compatibility with the latest RVV 1.0 standard. So 10xEngineers took on the project to add support for RVV version 1.0 to ARA.
This case study presents our experience in upgrading the ARA Vector processor to RVV 1.0 compatibility, focusing on the implementation of missing RVV permute, mask, fixed-point, and some of the RVV floating point instructions.
Objectives
The primary objectives of this project were:
- Update the ARA Vector processor to ensure compatibility with RVV 1.0.
- Implement missing permute, mask, floating point, and fixed-point instructions.
- Verify the functional correctness of the updated processor.
Solution:
To achieve the objectives, we followed a structured approach:
- RVV 1.0 Specification Study: Analyzed the RVV 1.0 specification to identify changes and additions.
- Gap Analysis: Identified missing instructions in the ARA Vector processor, including permute, mask, and fixed-point operations.
- Microarch Documents: Understood the ARA microarchitecture and added the microarchitecture documentation.
- Instruction Implementation: Designed and implemented the missing instructions:
- Permute instructions
- Mask instructions
- Fixed-point instructions
- Vector Floating point instructions
- Added support for shorter VLEN=128,256,512 in ARA
- Verification:
- Developed tests to verify the functionality and correctness of the implemented instructions.
- Ran regressions. Debugged and fixed RTL bugs.
Implementation Details
The following instructions were designed and added to the ARA.
RVV Mask Instructions
- vmsbf.m
- vmsif
- vmsof.m
- viota.m
- vid
- vcpop
- vfirst
RVV Permute Instructions
- vrgather
- vrgatherei16
- vcompress
RVV Fixed-Point Instructions
- vsmul
- vssra
- vssrl
- vnclup
- vnclipu
RVV Floating point
- vfrec7.v
- vfsqrt.v
- vfncvt.rod.f.f.w
Support for various VLENs
Ara supported the VLENs greater than or equal to 1024 bits. So, the support in the RTL was added to have VLENs equal to 128, 256, and 512 bits. To enable this, RTL was modified to have a single-lane configuration of ARA. Refer to PR#194 to see the detailed design implementation.
Conclusion
The successful upgrade of the ARA Vector processor to RVV 1.0 compatibility demonstrates the importance of staying updated with evolving standards. The implementation of missing instructions and adding support for various VLENs ensures the processor’s relevance in various applications, including scientific simulations, machine learning, and multimedia processing. This project contributes to the growing ecosystem of RISC-V-based Vector processors.