
Optimizing Floating-Point Support in Llama.cpp for RISC-V Vector (RVV)
Introduction and Hardware Context
Llama.cpp has become the standard runtime for running Large Language Models on CPUs. It supports a wide range of models and quantization formats with minimal setup, and its open-source community has driven strong performance on x86 and ARM. RISC-V, however, has lagged behind. Many of the core floating-point kernels had no RVV implementations and fell back to scalar code, and quantized vector-dot support was limited to legacy and K-Quant formats for vector lengths up to 256 bits. As RISC-V AI hardware matures and VLEN grows, this gap becomes increasingly costly.
This work was carried out by 10xEngineers in collaboration with RISE (RISC-V Software Ecosystem) under Project RP-014. RISE works towards strengthening the RISC-V software ecosystem, and RP-014 was scoped specifically to bring Llama.cpp’s RISC-V support closer to parity with x86 and ARM. Thanks to Dave Baker from Akeana and Ludovic Henry from RISE, who reviewed our work throughout. All work produced under this project is open-source and is being upstreamed to mainline Llama.cpp.
The project is covered across three blog posts:
- This first post focuses on floating-point kernel coverage: the core SIMD kernels, Llamafile SGEMM for prompt processing, and the Flash Attention GEMM.
- The second post covers quantization, specifically the vec-dot kernels we added for I-Quants, Ternary types, and MXFP4.
- The third post covers VLEN-aware data repacking and concludes with our testing framework.
Hardware Context
We benchmarked on the Banana Pi BPI-F3. It carries a SpacemiT X60 with eight cores, each implementing RVV at a 256-bit vector length (VLEN). When this project began it was one of the few boards shipping with RVV. Its microarchitecture and 256-bit VLEN were representative of what was commercially available then, so a configuration tuned here transfers to most of the hardware these kernels will run on. All kernel and end-to-end model benchmarks in this series were measured on this board. Functional correctness was checked on QEMU, which emulates RISC-V at a configurable VLEN, so we could verify every kernel across VLENs from 128 to 1024 bits without hardware beyond what was available at the time.
The floating-point kernels in this post use a single code path that covers VLEN 128 to 1024 with the LMUL and unrolling tuned for the 256-bit X60. The repack and quantized vector-dot kernels in the later posts diverge from this. Several are specialized per VLEN to make full use of the wider vectors that larger VLENs provide. A single generic kernel then handles everything above the largest VLEN we specialize for so the vector path still covers every VLEN.
Llama.cpp Execution Flow
GGML_OP operator and the operator sits in the hierarchy where threading is handled. When an operator runs it splits its output across the available threads and hands each thread a slice of the work. The thread then calls the floating-point compute kernels, the dot products, multiply-adds, scaling and conversions, to do the arithmetic on its slice. So the graph drives the ops, the ops spread the work across the eight cores and the kernels are the per-thread routines that we vectorize in this post.
Each kernel carries a SIMD implementation routed through a set of generic GGML macros and a scalar fallback for architectures without a vector path. We modify this flow by adding an explicit RVV exception inside the kernels because those generic SIMD mappings cannot be used directly on RVV, which is the subject of the next section.

Floating-Point Kernels
simd_mappings.h to write architecture agnostic kernels. These macros cover basic load and store operations alongside fused multiply-add and reduction sequences.
#define GGML_SIMD
// F32
#define GGML_F32_STEP 16
#define GGML_F32_EPR 4
#define GGML_F32x4 vfloat32m1_t
#define GGML_F32x4_ZERO __riscv_vfmv_v_f_f32m1(0.0f, GGML_F32_EPR)
#define GGML_F32x4_SET1(x) __riscv_vfmv_v_f_f32m1(x, GGML_F32_EPR)
#define GGML_F32x4_LOAD(x) __riscv_vle32_v_f32m1(x, GGML_F32_EPR)
#define GGML_F32x4_STORE(b, v) __riscv_vse32_v_f32m1(b, v, GGML_F32_EPR)
#define GGML_F32x4_FMA(a, b, c) __riscv_vfmacc_vv_f32m1(a, b, c, GGML_F32_EPR)
#define GGML_F32x4_ADD(a, b) __riscv_vfadd_vv_f32m1(a, b, GGML_F32_EPR)
#define GGML_F32x4_MUL(a, b) __riscv_vfmul_vv_f32m1(a, b, GGML_F32_EPR)
#define GGML_F32_VEC GGML_F32x4
#define GGML_F32_VEC_ZERO GGML_F32x4_ZERO
#define GGML_F32_VEC_SET1 GGML_F32x4_SET1
#define GGML_F32_VEC_LOAD GGML_F32x4_LOAD
#define GGML_F32_VEC_STORE GGML_F32x4_STORE
#define GGML_F32_VEC_FMA GGML_F32x4_FMA
#define GGML_F32_VEC_ADD GGML_F32x4_ADD
#define GGML_F32_VEC_MUL GGML_F32x4_MUL
#define GGML_F32_VEC_REDUCE GGML_F32x4_REDUCE
We encountered structural limitations when attempting to map these to RVV directly.
- Static LMUL Allocation The upstream implementation locked LMUL at compile time. This prevented us from dynamically tuning register usage across different kernels.
- Type Portability Issues Macros utilizing array-like accumulators failed to map cleanly to RVV intrinsics due to strict C++ type restrictions on vector types.
- Our Solution We bypassed the generic mappings entirely by implementing explicit per-kernel fallbacks to write the kernels directly using inline assembly or intrinsics.
void ggml_kernel(int n, float *s, ggml_fp16_t *x, ggml_fp16_t *y) {
#if defined(GGML_SIMD)
// SIMD/Vector Route
#if defined(__ARM_FEATURE_SVE)
// ARM SVE Implementation
// ...
#elif defined(__riscv_v_intrinsic)
// RVV Implementation
// ...
#else
// SIMD Mappings
// ...
#endif
#else
// Scalar Route
// ...
#endif
}
| Kernel | Operation | Data Types |
|---|---|---|
ggml_vec_dot_f16 |
s = Σ x[i]·y[i] | x, y in FP16 and s in FP32 |
ggml_vec_dot_f16_unroll |
s[j] = Σ x[i]·y[j][i] over rows j | x, y in FP16 and s in FP32 |
ggml_vec_dot_bf16 |
s = Σ x[i]·y[i] | x, y in BF16 and s in FP32 |
ggml_vec_mad_f16 |
y[i] = y[i] + a·x[i] | x, y in FP16 and a in FP32 |
ggml_vec_scale_f16 |
x[i] = a·x[i] | x in FP16 and a in FP32 |
ggml_cpu_fp16_to_fp32 |
y[i] = x[i] | x in FP16 and y in FP32 |
ggml_cpu_bf16_to_fp32 |
y[i] = x[i] | x in BF16 and y in FP32 |
ggml_vec_silu_f32 |
y[i] = x[i]·σ(x[i]) | x, y in FP32 |
ggml_vec_dot_f16 shows the pattern that most of these kernels follow. The scalar fallback iterates over the two FP16 arrays, widens each element to FP32 then multiplies and accumulates into an FP32 running sum. Our RVV implementation loads the FP16 inputs with __riscv_vle16_v_f16m1, accumulates products into an FP32 vector using the widening multiply-accumulate __riscv_vfwmacc_vv_f32m2 and finishes with a __riscv_vfredusum_vs_f32m8_f32m1 reduction that collapses the vector into the scalar result. The widening step is what bounds the register budget. The FP32 accumulator occupies twice the register space of the FP16 input so we cannot push this kernel past LMUL=4 without spilling to the stack.
The same widen, compute and narrow shape covers most of the group. ggml_vec_dot_f16 is the representative case.
void ggml_vec_dot_f16(int n, float *s, ggml_fp16_t *x, ggml_fp16_t *y) {
#if defined(GGML_SIMD)
// SIMD/Vector Route
#if defined(__ARM_FEATURE_SVE)
// ARM SVE Implementation
// ...
#elif defined(__riscv_v_intrinsic)
// RVV Implementation
int vl = __riscv_vsetvlmax_e32m2();
vfloat32m1_t vs = __riscv_vfmv_v_f_f32m1(0.0f, 1);
vfloat32m2_t vsum;
vfloat16m1_t ax;
vfloat16m1_t ay;
vsum = __riscv_vreinterpret_v_u32m2_f32m2(__riscv_vmv_v_x_u32m2(0, vl));
for (int i = 0; i < n; i += vl) {
vl = __riscv_vsetvl_e16m1(n - i);
ax = __riscv_vle16_v_f16m1_tu(ax, (const _Float16 *)&x[i], vl);
ay = __riscv_vle16_v_f16m1_tu(ay, (const _Float16 *)&y[i], vl);
vsum = __riscv_vfwmacc_vv_f32m2_tu(vsum, ax, ay, vl);
}
vl = __riscv_vsetvlmax_e32m1();
vfloat32m1_t ac0 = __riscv_vfadd_vv_f32m1(__riscv_vget_v_f32m2_f32m1(vsum, 0), __riscv_vget_v_f32m2_f32m1(vsum, 1), vl);
vs = __riscv_vfredusum_vs_f32m1_f32m1(ac0, vs, vl);
sumf += __riscv_vfmv_f_s_f32m1_f32(vs);
#else
// SIMD Mappings
// ...
#endif
#else
// Scalar Route
for (int i = 0; i < n; ++i) {
sumf += (ggml_float)(GGML_CPU_FP16_TO_FP32(x[i])*GGML_CPU_FP16_TO_FP32(y[i]));
}
#endif
}
// Inner loop with LMUL=2 and Unroll=2
for (int i = 0; i < n; i += step) {
vfloat16m2_t ax0 = __riscv_vle16_v_f16m2(&x[i], epr);
vfloat16m2_t ay0 = __riscv_vle16_v_f16m2(&y[i], epr);
vsum0 = __riscv_vfwmacc_vv_f32m4(vsum0, ax0, ay0, epr);
vfloat16m2_t ax1 = __riscv_vle16_v_f16m2(&x[i + epr], epr);
vfloat16m2_t ay1 = __riscv_vle16_v_f16m2(&y[i + epr], epr);
vsum1 = __riscv_vfwmacc_vv_f32m4(vsum1, ax1, ay1, epr);
}
These are single-core measurements.
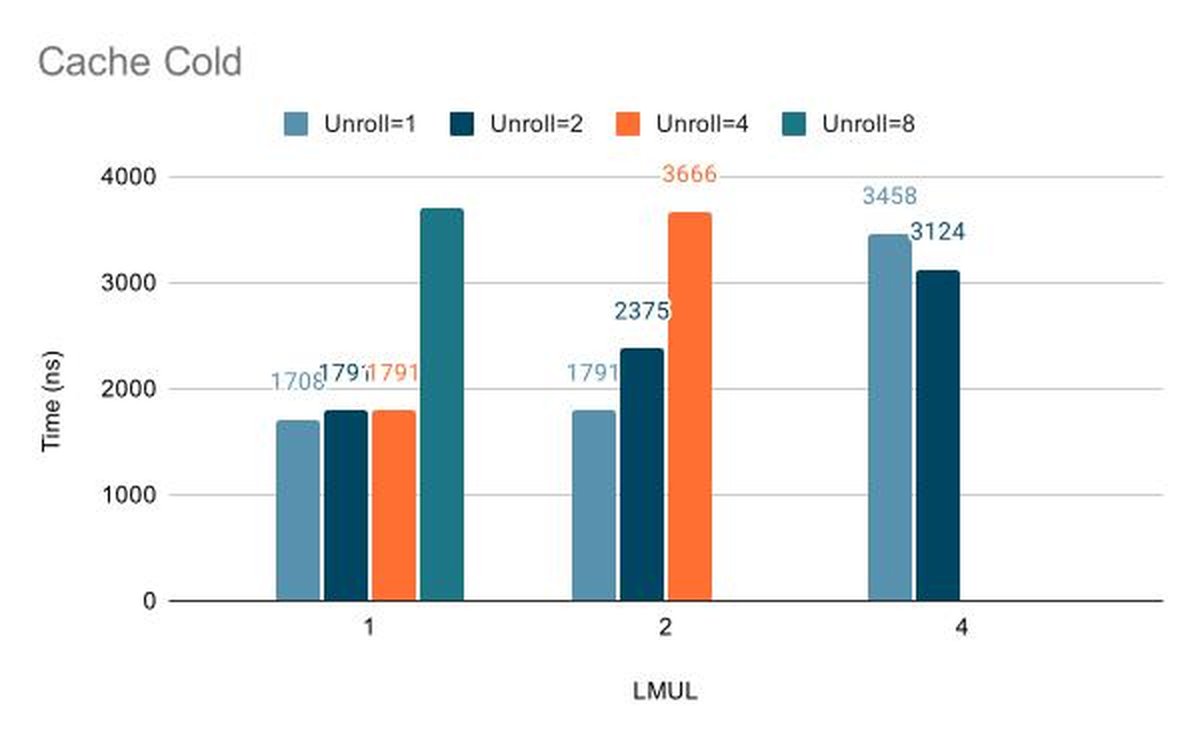
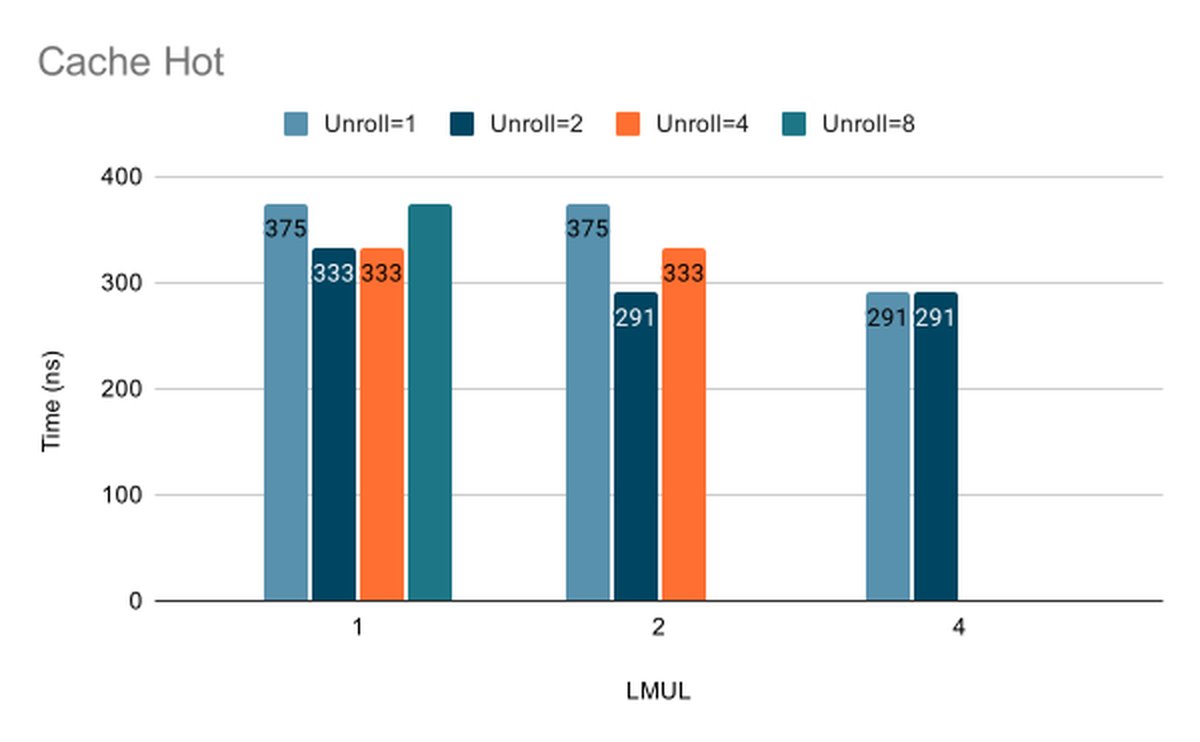
The two cache states pull the result in opposite directions and that is what makes the sweep worth running. When the data is cold the kernel waits on memory and the loads dominate the runtime. When the data is hot the loads are cheap and the multiply-accumulate becomes the limit. A configuration that wins cold does not have to win hot. We weigh the hot-cache time because the kernel is called repeatedly on resident data during inference, but we do not select on the hot number alone. A configuration that is fastest hot but much slower cold loses to one that gives up a little hot time while holding near the best cold time. A few nanoseconds of hot time does not justify a cold time that runs hundreds of nanoseconds slower. For ggml_vec_dot_f16 the widening accumulation caps us at LMUL=4 and we skipped unrolling factor 8 at LMUL=4 because it exceeds the physical register file and forces spilling.
| Kernel | LMUL | Unrolling | Cache Cold (ns) | Cache Hot (ns) |
|---|---|---|---|---|
vec_dot_f16_scalar | Auto | Auto | 3687 | 2625 |
vec_dot_f16 | 1 | 1 | 1708 | 375 |
vec_dot_f16 | 1 | 2 | 1791 | 333 |
vec_dot_f16 | 1 | 4 | 2208 | 333 |
vec_dot_f16 | 1 | 8 | 3708 | 375 |
vec_dot_f16 | 2 | 1 | 1791 | 375 |
vec_dot_f16 | 2 | 2 | 2375 | 291 |
vec_dot_f16 | 2 | 4 | 3666 | 333 |
vec_dot_f16 | 4 | 1 | 3458 | 291 |
vec_dot_f16 | 4 | 2 | 3124 | 291 |
We selected LMUL=2 with unroll factor 2. It holds the cache-hot time at 291ns where the multiply is the bottleneck while keeping the cache-cold time competitive at 2375ns.
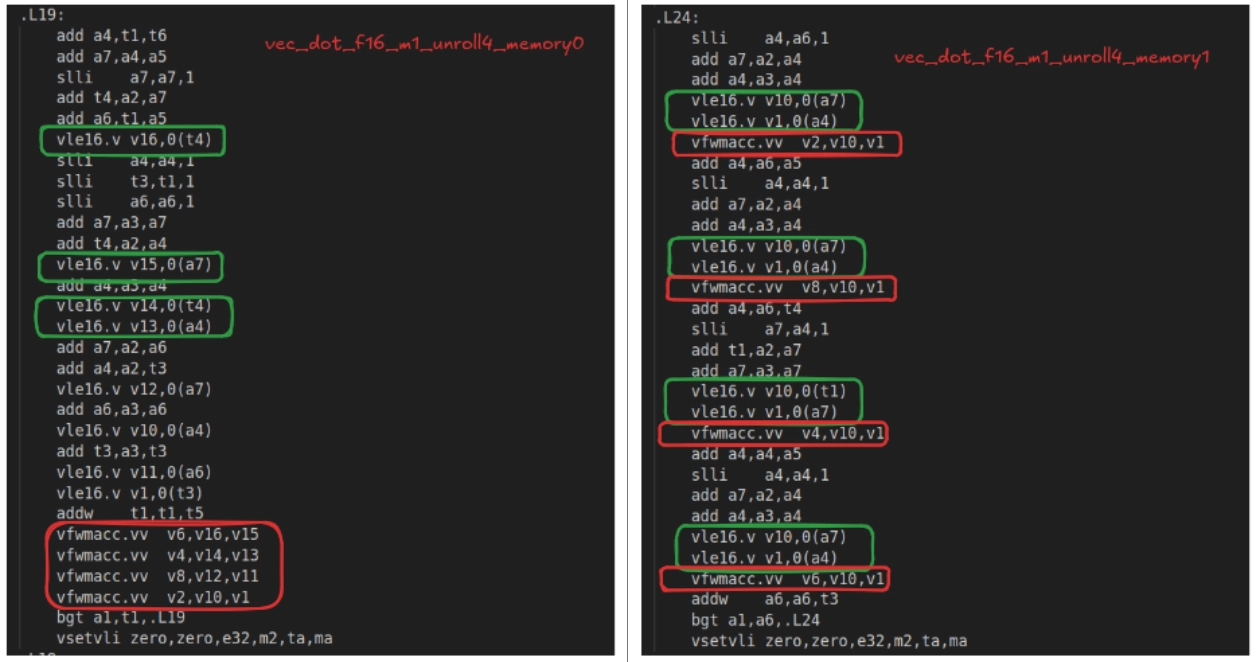
asm volatile("" ::: "memory")) after each accumulate to stop the compiler reordering memory operations across it and preserve the interleaving of loads and multiplies we intended.
for (int i = 0; i < n; i += step) {
vfloat16m1_t ax0 = __riscv_vle16_v_f16m1(&x[i], epr);
vfloat16m1_t ay0 = __riscv_vle16_v_f16m1(&y[i], epr);
vsum0 = __riscv_vfwmacc_vv_f32m2(vsum0, ax0, ay0, epr);
asm volatile ("" ::: "memory");
vfloat16m1_t ax1 = __riscv_vle16_v_f16m1(&x[i + epr], epr);
vfloat16m1_t ay1 = __riscv_vle16_v_f16m1(&y[i + epr], epr);
vsum1 = __riscv_vfwmacc_vv_f32m2(vsum1, ax1, ay1, epr);
__asm__ __volatile__ ("" ::: "memory");
vfloat16m1_t ax2 = __riscv_vle16_v_f16m1(&x[i + 2 * epr], epr);
vfloat16m1_t ay2 = __riscv_vle16_v_f16m1(&y[i + 2 * epr], epr);
vsum2 = __riscv_vfwmacc_vv_f32m2(vsum2, ax2, ay2, epr);
__asm__ __volatile__ ("" ::: "memory");
vfloat16m1_t ax3 = __riscv_vle16_v_f16m1(&x[i + 3 * epr], epr);
vfloat16m1_t ay3 = __riscv_vle16_v_f16m1(&y[i + 3 * epr], epr);
vsum3 = __riscv_vfwmacc_vv_f32m2(vsum3, ax3, ay3, epr);
__asm__ __volatile__ ("" ::: "memory");
}
For ggml_vec_dot_f16 this single change improved the execution time for cache cold cases.
| Kernel | LMUL | Unrolling | Compiler Barrier | Cache Cold (ns) | Cache Hot (ns) |
|---|---|---|---|---|---|
vec_dot_f16_scalar | Auto | Auto | No | 3687 | 2625 |
vec_dot_f16 | 1 | 1 | No | 1708 | 375 |
vec_dot_f16 | 1 | 2 | No | 1791 | 333 |
vec_dot_f16 | 1 | 2 | Yes | 1833 | 333 |
vec_dot_f16 | 1 | 4 | No | 2208 | 333 |
vec_dot_f16 | 1 | 4 | Yes | 1999 | 375 |
vec_dot_f16 | 1 | 8 | No | 3708 | 375 |
vec_dot_f16 | 1 | 8 | Yes | 1791 | 375 |
vec_dot_f16 | 2 | 1 | No | 1791 | 375 |
vec_dot_f16 | 2 | 2 | No | 2375 | 291 |
vec_dot_f16 | 2 | 2 | Yes | 1917 | 291 |
vec_dot_f16 | 2 | 4 | No | 3666 | 333 |
vec_dot_f16 | 2 | 4 | Yes | 1791 | 333 |
vec_dot_f16 | 4 | 1 | No | 3458 | 291 |
vec_dot_f16 | 4 | 2 | No | 3124 | 291 |
vec_dot_f16 | 4 | 2 | Yes | 3333 | 333 |
We also used this compiler barrier in some other kernels to prevent instructions from reordering which was causing increased register pressure and spilling resulting in degraded performance. We will discuss those kernels in the next blog.
The remaining kernels were swept the same way. The BF16 dot ggml_vec_dot_bf16 folds the widening into the multiply with __riscv_vfwmaccbf16_vv_f32m8 followed by the same reduction as ggml_vec_dot_f16. The conversion kernels ggml_cpu_fp16_to_fp32 and ggml_cpu_bf16_to_fp32 are the same pattern with the arithmetic removed, a widening convert through __riscv_vfwcvt_f_f_v_f32m8 and __riscv_vfwcvtbf16_f_f_v_f32m8 respectively. The FP16 to FP32 convert takes no compiler barrier because there is no multiply to keep separated from the loads.
The BPI-F3 does not have hardware BF16 support so the two BF16 kernels ggml_vec_dot_bf16 and ggml_cpu_bf16_to_fp32 could not be benchmarked on it. We selected their configuration from the guidelines the other kernels gave us. The BF16 dot follows ggml_vec_dot_f16 and the BF16 to FP32 convert follows ggml_cpu_fp16_to_fp32. Correctness was validated on QEMU.
The unrolled dot product ggml_vec_dot_f16_unroll already unrolls across two input rows internally, so adding our own unrolling and the barrier both reduced its throughput. The compiler does not auto-vectorize the scalar ggml_vec_silu_f32 at all, so it runs above 54000ns and the vectorized path improves on its own at any configuration.
The final selected configurations are listed below. The times are standalone single-core nanoseconds at a 1024-element input, measured the same way as ggml_vec_dot_f16.
| Kernel | LMUL | Unrolling | Compiler Barrier | Cache Cold (ns) | Cache Hot (ns) |
|---|---|---|---|---|---|
vec_dot_f16_unroll | 2 | 2 | No | 3875 | 458 |
vec_silu_f32 | 2 | 1 | N/A | 7041 | 6083 |
cpu_fp16_to_fp32 | 2 | 2 | No | 2125 | 416 |
All the floating-point kernels in this section were benchmarked against the scalar reference with our own perf-float.cpp, which we added to the llama.cpp-validation repo because upstream Llama.cpp does not cover these kernels. It reports throughput in MFLOPS at a given vector size. The speedup over the scalar reference is below.
| Kernel | 512 | 1024 | 2048 |
|---|---|---|---|
ggml_vec_dot_f16_unroll | 9x | 11x | 12.73x |
ggml_vec_silu_f32 | 10.95x | 11.18x | 11.29x |
ggml_cpu_fp16_to_fp32 | 5.61x | 6.92x | 7.76x |
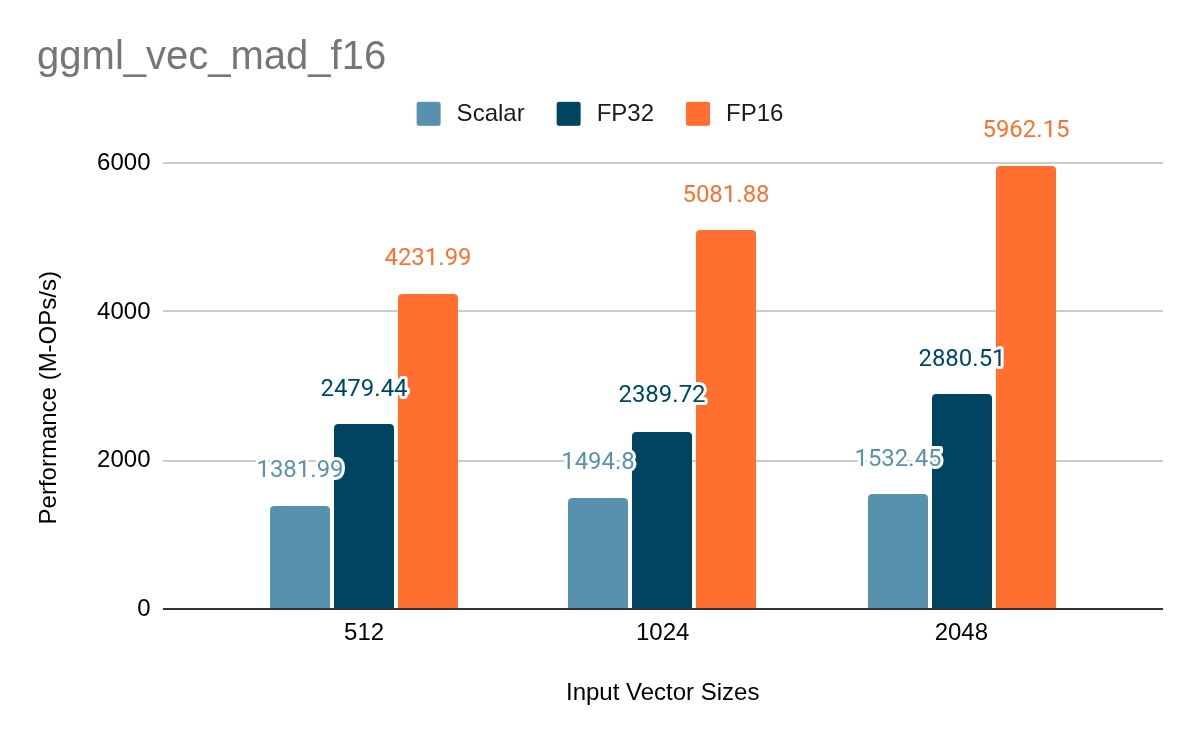
Additionally, for the multiply-add kernel ggml_vec_mad_f16 and the scaling kernel ggml_vec_scale_f16 , we looked into one more optimization. The default pattern widens the FP16 data to FP32, runs the arithmetic against the FP32 scalar that Llama.cpp passes in then narrows the result back to FP16. We downcast that scalar to FP16 once at the top of the kernel and run the multiply directly on the FP16 data, which drops the __riscv_vfwcvt and __riscv_vfncvt instructions from the loop body. ggml_vec_mad_f16 computes y[i] = y[i] + a·x[i] and ggml_vec_scale_f16 computes x[i] = a·x[i] so both come down to one FP16 multiply per element once the scalar is converted. The average error against the scalar reference is about 0.004f with the FP16 multiply and under 0.001f with the FP32 multiply, the same for both kernels.
Both were swept the same way and settled on the same configuration.
| Kernel | LMUL | Unrolling | Compiler Barrier | Cache Cold (ns) | Cache Hot (ns) |
|---|---|---|---|---|---|
vec_mad_f16 | 4 | 2 | Yes | 2250 | 375 |
vec_scale_f16 | 4 | 2 | Yes | 1500 | 291 |
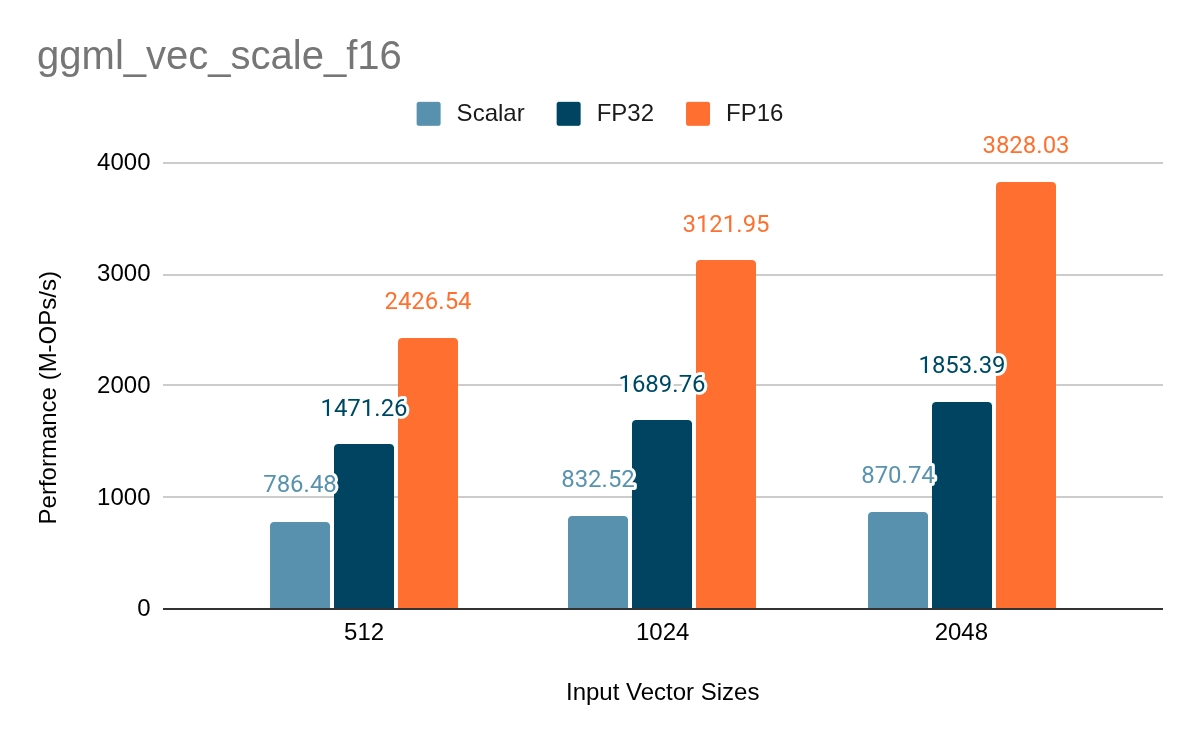
The plots below hold that configuration fixed and compare the FP32 arithmetic path against the FP16 path for each kernel. The scaling kernel shows roughly a 1.8x to 2x gain
The vectorized ggml_vec_dot_f16 from the previous section computes one output element from a pair of rows. That fits token generation where each step multiplies a single activation row against the weights. Prompt processing is different. It multiplies many activation rows at once, which is a dense matrix-matrix product and computing that one dot product at a time leaves each loaded weight row underused. Llama.cpp already ships a tiled matrix-matrix kernel for this case in the Llamafile SGEMM library, with paths for x86, ARM and PowerPC but none for RVV, so prefill on RISC-V fell back to the per-row dot.
We added an RVV path directly into ggml-cpu/llamafile/sgemm.cpp
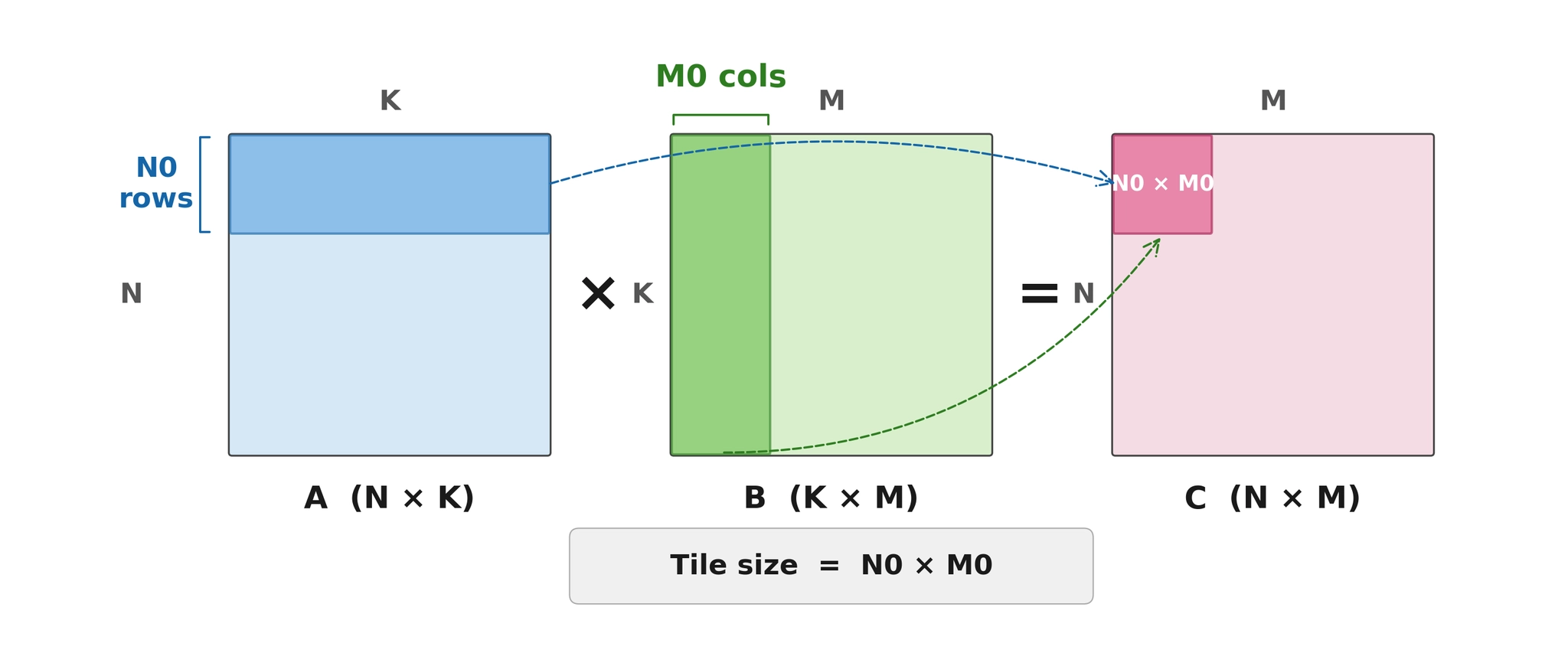
Figure 2 shows the tiled inner-product matmul. So, each kernel call processes N0 rows of the LHS with M0 cols of the RHS resulting in an N0 x M0 tiled output. In practice, both matrices are laid out contiguously so B is transposed as well.
The code below shows the core inner loop: for each tile, we load N0 and M0 rows of A and B, multiply and accumulate and then reduce the final result into the N0 x M0 output.
template <int M0, int N0>
inline void gemm_bloc(int64_t ii, int64_t jj) {
D Cv[N0][M0] = {}; // Accumulators based on tile size for N0 x M0
for (int64_t l = 0; l < k; l += K0) { // Iterate over full rows
// Load all rows of A.
V Av[N0];
for (int64_t j = 0; j < N0; ++j) {
Av[j] = load<V>(A + lda * (jj + j) + l);
}
// Load 1 row of B and accumulate
for (int64_t i = 0; i < M0; ++i) {
V Bv = load<V>(B + ldb * (ii + i) + l);
for (int64_t j = 0; j < N0; ++j) {
Cv[j][i] = madd(Bv, Av[j], Cv[j][i]);
}
}
}
// Reduce
for (int64_t j = 0; j < N0; ++j) {
for (int64_t i = 0; i < M0; ++i) {
C[ldc * (jj + j) + (ii + i)] = hsum(Cv[j][i]);
}
}
}
Our implementation dispatches through a tinyBLAS_RVV template that selects the tile from the M dimension and the active LMUL. The inner gemm_bloc accumulates into an array of vector registers Cv[N0][M0], iterates over K loading the rows of B and the matching row of A, multiplies them with the fused madd and horizontally reduces each accumulator into the output matrix C at the end. The template orders its dimensions M0then N0 so the 6x4 tile is M0=4 and N0=6 in the code above.
The size of the tile each thread works on is bounded by the vector register file. A tile of N0 x M0 holds N0 times M0 running accumulators in registers, plus the input rows it multiplies and the whole working set has to fit in the 32 architectural vector registers or the compiler spills to the stack.
RVV gives us a knob the fixed-width architectures do not have. Raising LMUL groups several physical registers into one logical register, so a higher LMUL leaves fewer logical registers but each one holds more data. We use this to trade register count against tile shape and arrive at three candidate tiles. The accumulators are FP32 widened from the FP16 inputs so each one occupies LMUL registers. A 6x4 tile holds 24 accumulators at LMUL=1, a 3x4 tile holds 12 at LMUL=2 which is the same 24 registers and a 2x2 tile holds 4 at LMUL=4 for 16 registers. Adding the FP16 input rows keeps all three within the 32-register file.
The table below shows tile budgeting for FP16 x FP16 = FP32:
| Tile | LMUL | Accumulator Registers | LHS Registers | RHS Registers | Total Registers |
|---|---|---|---|---|---|
| 6×4 | 1 | 6 x 4 x m1 = 24 | 1 x mf2 = 1 | 6 x mf2 = 6 | 31 |
| 3×4 | 2 | 3 x 4 x m2 = 24 | 3 x m1 = 6 | 1 x m1 = 1 | 31 |
| 2×2 | 4 | 2 x 2 x m4 = 16 | 2 x m2 = 4 | 2 x m2 = 4 | 24 |
We benchmarked the three tiles across the M, N and K dimensions of typical TinyLlama and BERT shapes, with the thread count fixed at 8. The table below is a representative sample of the best total time in microseconds.
| Type | M | N | K | 6×4 (LMUL=1) Time (us) | 3×4 (LMUL=2) Time (us) | 2×2 (LMUL=4) Time (us) |
|---|---|---|---|---|---|---|
| F16 | 64 | 32 | 256 | 67 | 53 | 47 |
| F16 | 256 | 32 | 64 | 35 | 46 | 42 |
| F16 | 2048 | 32 | 2048 | 16956 | 16250 | 13918 |
| F16 | 5632 | 32 | 2048 | 46740 | 44754 | 38611 |
| F16 | 64 | 64 | 256 | 147 | 95 | 83 |
| F16 | 2048 | 64 | 2048 | 38864 | 32599 | 27780 |
| F16 | 5632 | 64 | 2048 | 106311 | 89331 | 77520 |
| F16 | 256 | 128 | 64 | 192 | 183 | 163 |
| F16 | 2048 | 128 | 2048 | 77755 | 64100 | 55649 |
| F16 | 5632 | 128 | 2048 | 213160 | 176006 | 155001 |
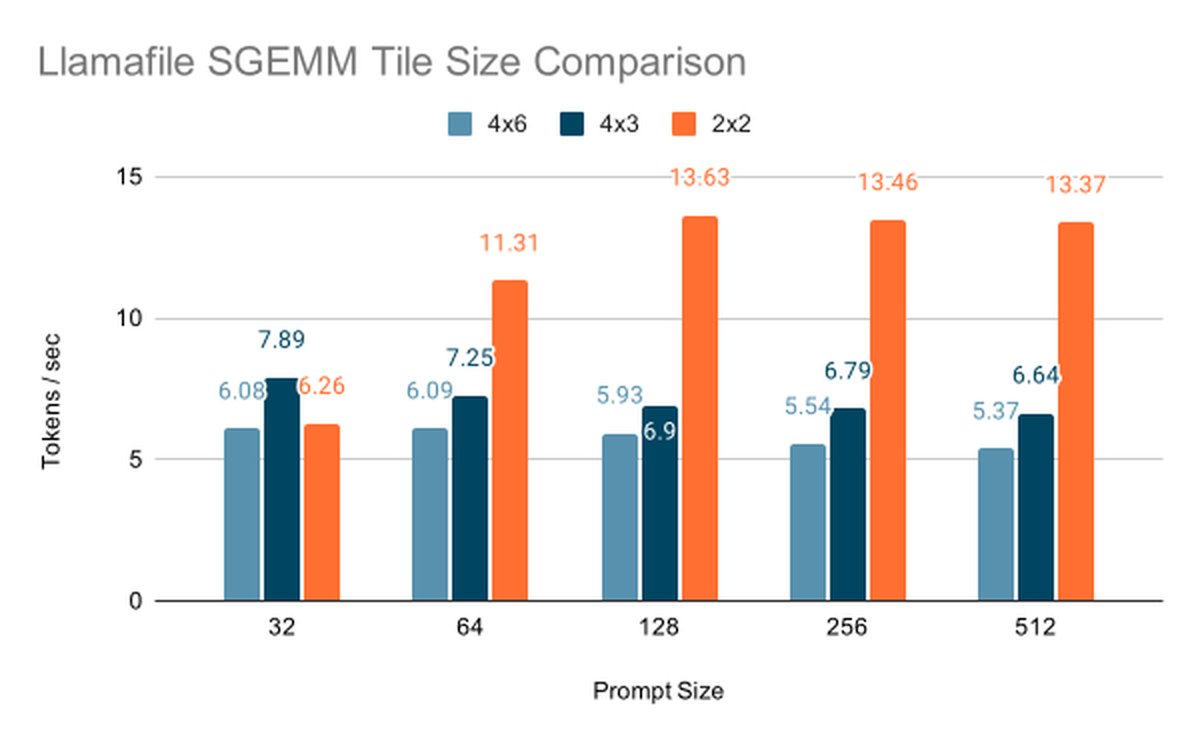
The 2x2 tile is fastest on the large shapes, the ones with M and K in the thousands that account for most of the prefill cost. On the small shapes the 6x4 tile occasionally edges ahead, for example at M=256 N=32 K=64, but those cases are cheap enough that the gap does not move the end-to-end time. The graph below summarizes the end-to-end on TinyLlama 1.1B.
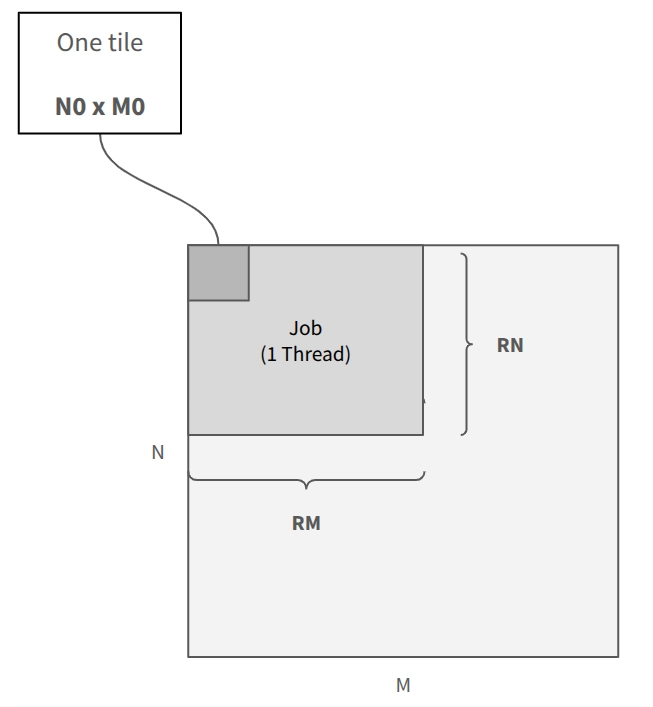
Tile size is one of two parameters the kernel exposes. The other is the job size, the number of tiles along the M and N dimension (RM and RN) a single thread processes before another thread picks up the next block.
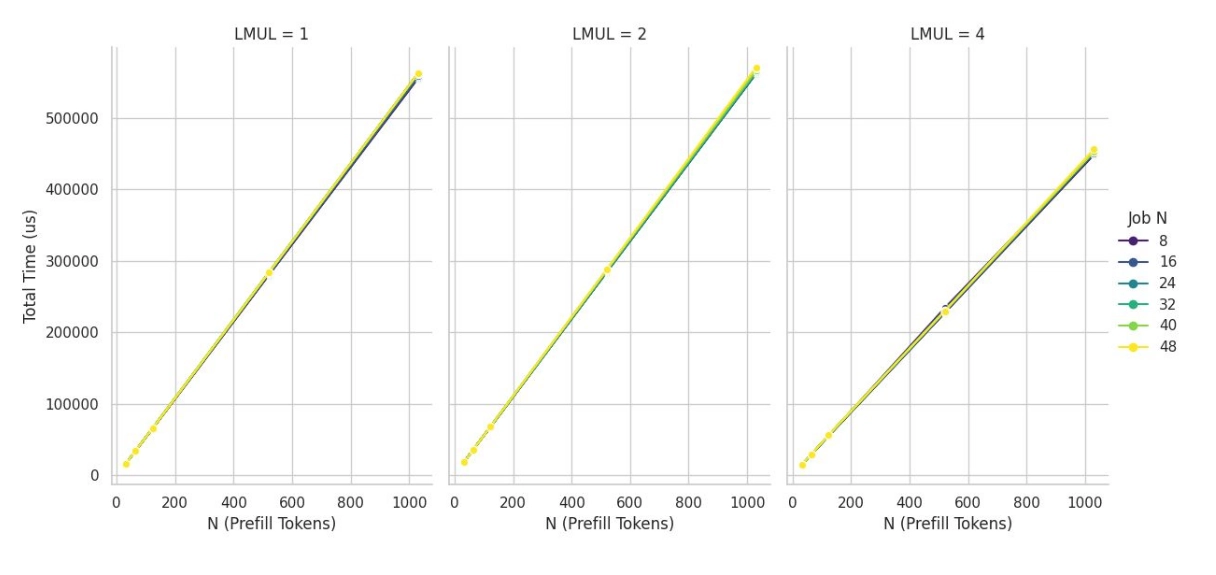
We then measured prompt processing on the Banana Pi BPI-F3 with the TinyLlama F16 1.1B model, comparing each tile against the per-row
path.
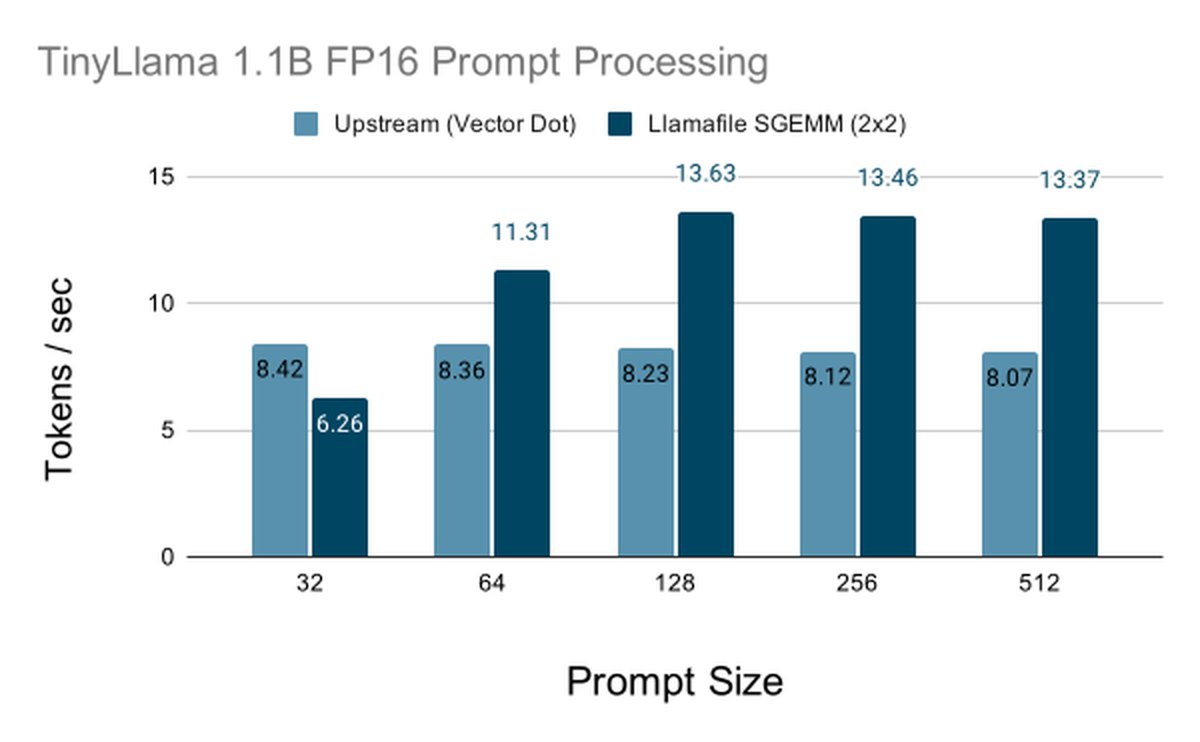
Below a prompt size of 64 the per-row vec_dot is still faster because there are too few rows to fill a tile. At prompt size 64 the 2×2 SGEMM overtakes it and by 128 it reaches 13.73 tokens per second against 8.78 for vec_dot. Prefill runs on long prompts so we shipped the 2×2 tile at LMUL=4.
Overall, SGEMM gives us around 1.5x performance over upstream vector dot. In the blogs to follow, we’ll discover how introduced data repacking further boosts performance for prompt processing.
Flash Attention
We next optimized the attention mechanism, which is a primary compute cost during inference. Llama.cpp uses a Flash Attention path that fuses the three steps of attention into a single pass. It computes the dot product of the Query and Key matrices, applies the softmax normalization and multiplies the result by the Value matrix without ever materializing the full attention matrix in memory.
The CPU Flash Attention implementation routes through three paths depending on the sequence length and the data types.
| Path | Condition | Description |
|---|---|---|
| Split-KV (decode) | n_seq == 1, n_kv ≥ 512, K and V are F16/F32 of the same type | All threads process the same head but a different chunk of the KV cache then combine their partial results. Parallelism is n_heads × n_threads. |
| Tiled (prefill) | n_seq ≥ 64, Q is F32, K and V are F16/F32 of the same type | Processes tiles of 64 queries against tiles of 64 KV positions, using GEMM blocks for both the Q·Kᵀ scores and the softmax(scores)·V weighting. |
| Non-tiled (fallback) | Everything else, or forced through the reference flag | Each thread processes one query head against the complete KV cache. Parallelism is n_heads. |
Prompt processing runs through the Tiled path so that is where we focused. That path runs two GEMM blocks that carry most of the work, the Q·Kᵀ score computation and the softmax(scores)·V weighting. On RISC-V both of them fell back to a scalar implementation while the other architectures ran vector math. Neither the Llamafile SGEMM from the previous section nor the standard ggml_mul_mat op fits here. Both of those compute A × Bᵀ, the shape you want when a weight matrix multiplies an activation matrix. The attention blocks instead multiply two activation tiles against each other and need a plain A × B with no transpose. So we wrote a separate vectorized RVV GEMM for these 64×64 tiles. The kernel keeps up to 7 rows of C in LMUL=4 accumulator groups and walks the K dimension one row of B at a time. Each step loads a single B vector and runs one vfmacc per row, broadcasting the matching element of A, so the loaded B vector is reused across all 7 rows while one of the eight register groups stays free for the next B load.
To measure the kernel on its own we benchmarked the vectorized GEMM with test-backend-ops using TinyLlama-1B attention parameters (head sizes hsk and hsv of 64, 4 heads, FP32 accumulation and an FP16 KV cache).
| Tokens | Upstream GFLOPS | Vectorized GFLOPS | Speedup |
|---|---|---|---|
| 128 | 2.69 | 22.75 | 8.46x |
| 256 | 2.49 | 23.70 | 9.52x |
| 512 | 2.69 | 24.07 | 8.95x |
| 1024 | 2.60 | 24.43 | 9.40x |
| 2048 | 2.64 | 23.48 | 8.90x |
| 4096 | 2.72 | 23.16 | 8.51x |
| 8192 | 2.73 | 22.18 | 8.13x |
The vectorized kernel raised the math throughput from under 3 GFLOPS to around 24 GFLOPS, an 8x to 9x gain that holds steady across token counts. We then measured the end-to-end effect with llama-bench on the TinyLlama 1B FP32 model to see how much of that reached prompt processing.
| Prompt Size | Upstream (tok/s) | Vectorized (tok/s) | Speedup |
|---|---|---|---|
| 128 | 8.44 | 8.85 | 1.05x |
| 256 | 8.16 | 8.86 | 1.09x |
| 512 | 7.55 | 8.76 | 1.16x |
The isolated kernel is 9x faster but end-to-end prefill improves by about 16 percent at a prompt size of 512. The two GEMM blocks are only a part of the total prefill compute so the fraction of time they occupied caps how far their speedup can move the whole pass. This is Amdahl’s Law and it is why we report the kernel result and the model result side by side rather than the kernel result alone.
Conclusion
This post covered the floating-point work, the vectorized compute kernels, the 2×2 Llamafile SGEMM tile for prefill and the RVV GEMM for the Flash Attention tiles. Together they move floating-point prompt processing on the BPI-F3 well past the upstream scalar baseline.
The next post moves to quantization. We extend vector-dot support to the quantization types that upstream RISC-V lacked and cover the kernels that needed VLEN-specific work. The last post will introduce VLEN-aware repacking, which repacks the weight matrices ahead-of-time for improved prompt processing performance. It pushes floating-point prefill past the Llamafile SGEMM shown here and applies the same approach to the matmul path for quantized weights.