AI INFRASTRUCTURE SOFTWARE · 10XENGINEERS
QuantX
Hardware-Aware Quantization for AI Inference IP Architects
Designing AI inference silicon requires critical decisions on numeric formats and architecture. QuantX brings hardware evaluation into the design loop, enabling early validation of correctness, accuracy, and performance before tape-out.
1B–14B+
Parameters — model range currently supported
*New models on the active roadmap
8+
Outlier reduction and rounding techniques supported
*More techniques on the roadmap
4
Custom numeric formats: MXFP · BFP · NVFP · FP16+INT
*Any arbitrary combination of numerics supported
PLATFORM OVERVIEW
What QuantX Does
QuantX is a hardware-aware design-space exploration platform. Unlike general-purpose post-training quantization tools designed for ML engineers, QuantX is designed for the upstream decision: choosing the number representation hard-wired into your datapath.
Design-Space Exploration
Sweep custom numeric formats — MXFP, BFP, NVFP, FP16+INT — against real LLM and VLM workloads. Identify the accuracy-efficiency Pareto frontier before RTL freeze.
Hardware Validation Closure
Use QuantX as your golden reference model. Its software-simulated quantization is parameterised to match your hardware's numeric format and datapath behaviour exactly.
Inference SDK Deployment
Deploy QuantX-compressed models into your existing inference SDK — or engage 10xEngineers to build your inference SDK from the ground up, purpose-fitted to your hardware.
Automation That Replaces Manual Sweeps
QuantX's meta-optimization engine automatically allocates bit widths and selects the active algorithm combination based on your memory constraints. What previously took weeks now runs as a feed-forward pipeline.
NUMERIC FORMATS
Custom Numeric Format Support
QuantX supports four mainstream numeric format families (and customized combinations) being considered by major industry players for next-generation AI inference silicon.
| Format | Description |
|---|---|
| FP16+INT | 16-bit FP scaling factors and integer-quantized data elements |
| MXFP | OCP Microscaling format — Power-of-Two shared exponent blocks with FP data elements |
| NVFP | FP8 scale factors with FP4 data elements — NVIDIA's narrow-precision inference format |
| BFP | Block Floating Point — PoT shared exponent with integer mantissas |
| Custom | Any arbitrary combination of numerics supported |
AUTOMATION ENGINE
Meta-Optimization: Automated Multi-Level Bit Allocation
Given user-defined constraints on model weight storage and peak inference memory, meta-optimization allocates bit widths and selects the algorithm combination that best satisfies those constraints — operating feed-forward without iterative search.
Block-Level Importance Scoring
Tensor-Level Refinement
Format-Specific Algorithm Selection

MODEL SUPPORT
Supported Models
QuantX supports a curated and expanding set of open-weight LLMs and VLMs in the 1B–14B parameter range — the most commercially relevant deployment targets for custom AI inference silicon.
Language Models (LLMs)
Vision Language Models (VLMs)
Legacy & Generative Models
ARCHITECTURE
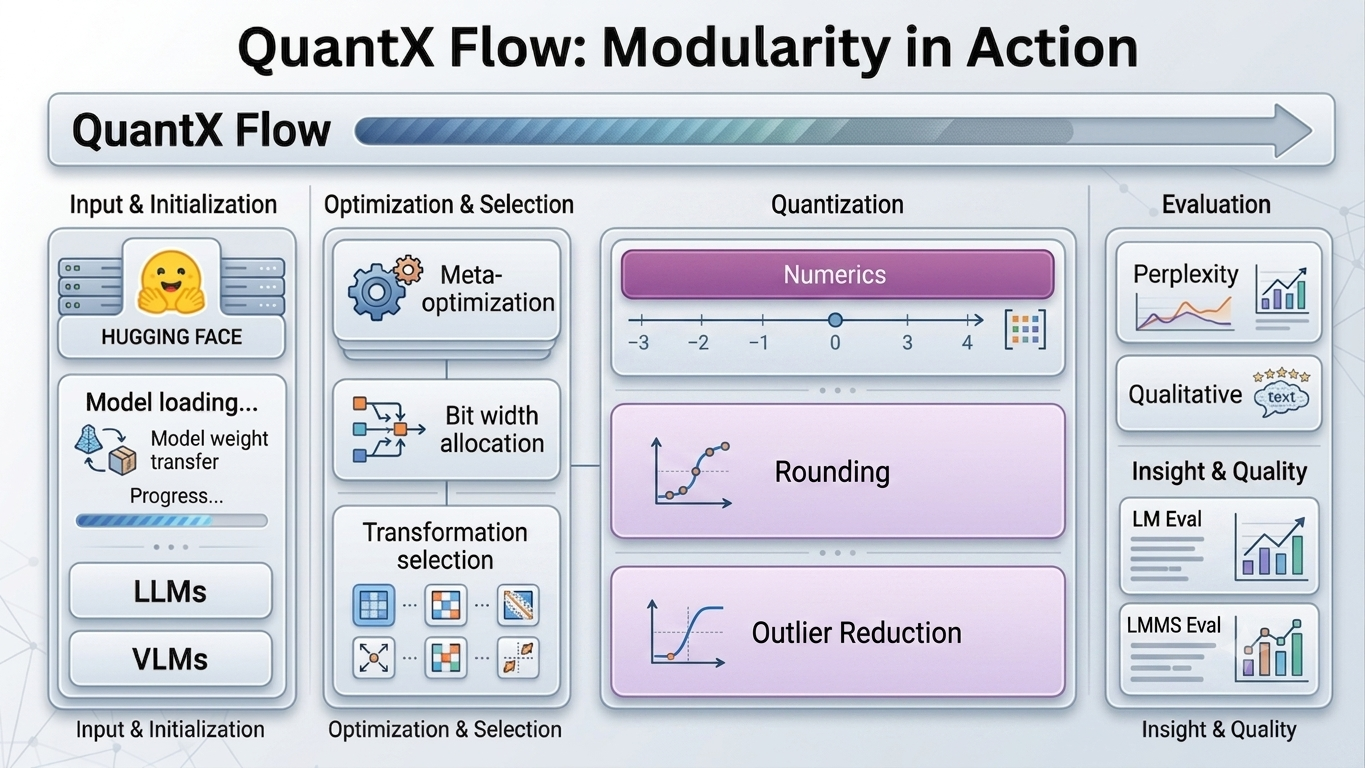
Modular Design: Built to Scale With Your Roadmap
QuantX is architected as a modular pipeline that decouples each stage of the quantization workflow. Adding a new numeric format, model, or evaluation metric requires extending a single module rather than refactoring the full pipeline.
The QuantX flow runs from HuggingFace model loading through meta-optimization, bit-width allocation, transformation selection, quantization (RTN / GPTQ), and evaluation.
Both language model evaluation (perplexity, ARC, GSM8K etc) and multimodal evaluation (TextVQA, MMBench, ChartQA etc) run natively, producing a comprehensive accuracy report in a single pipeline execution.
BENCHMARK RESULTS
Measured Accuracy Across Models & Formats
All results compare four QuantX configurations against the full-precision unquantized baseline. RTN is the accuracy floor; QuantX Performance is the best-effort configuration. All results are without any fine tuning.
INT + FP Format — Wikitext-2 Perplexity (lower is better)
BFP Format — Wikitext-2 Perplexity (lower is better)
ARC Challenge (higher is better)
GSM8K (higher is better)
INT + FP Format — TextVQA (higher is better)
BFP Format — MMBench (higher is better)
ChartQA (higher is better)
Key takeaway: Across all four model-format combinations, QuantX consistently and significantly outperforms vanilla RTN. On three of four benchmarks, QuantX Performance recovers more than 50% of the accuracy gap to baseline.
THE CONSOLE BEHIND THE NUMBERS
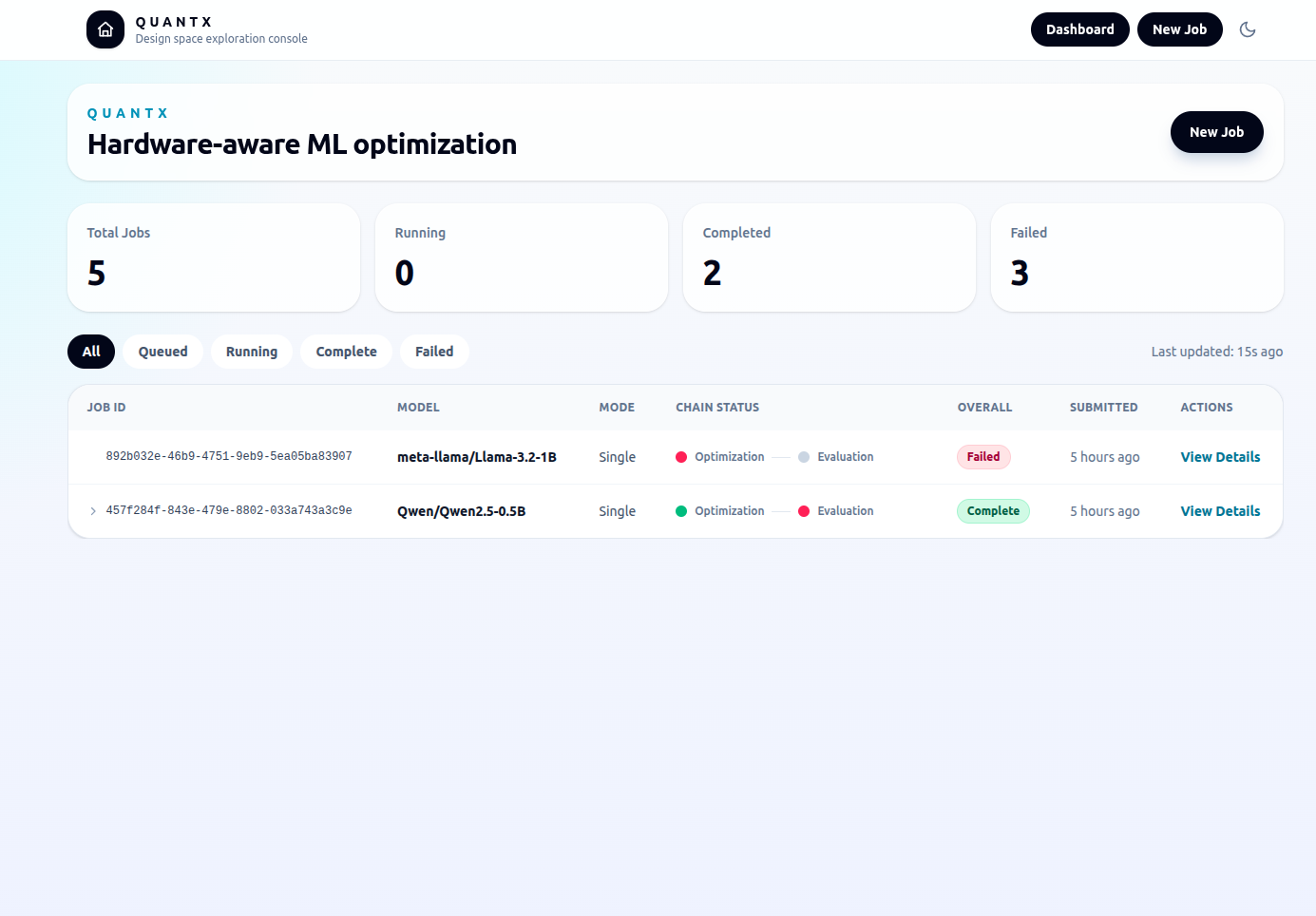
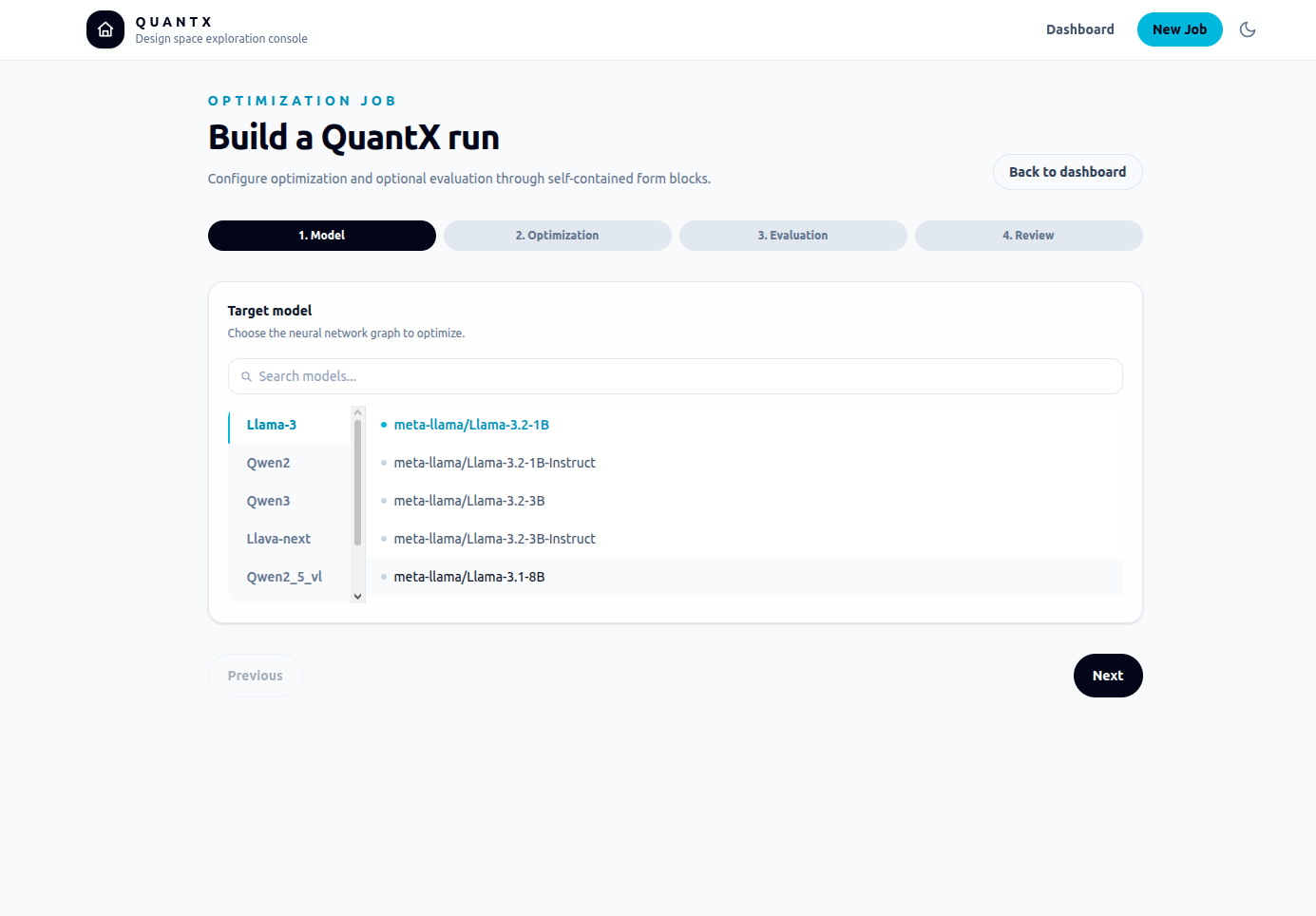
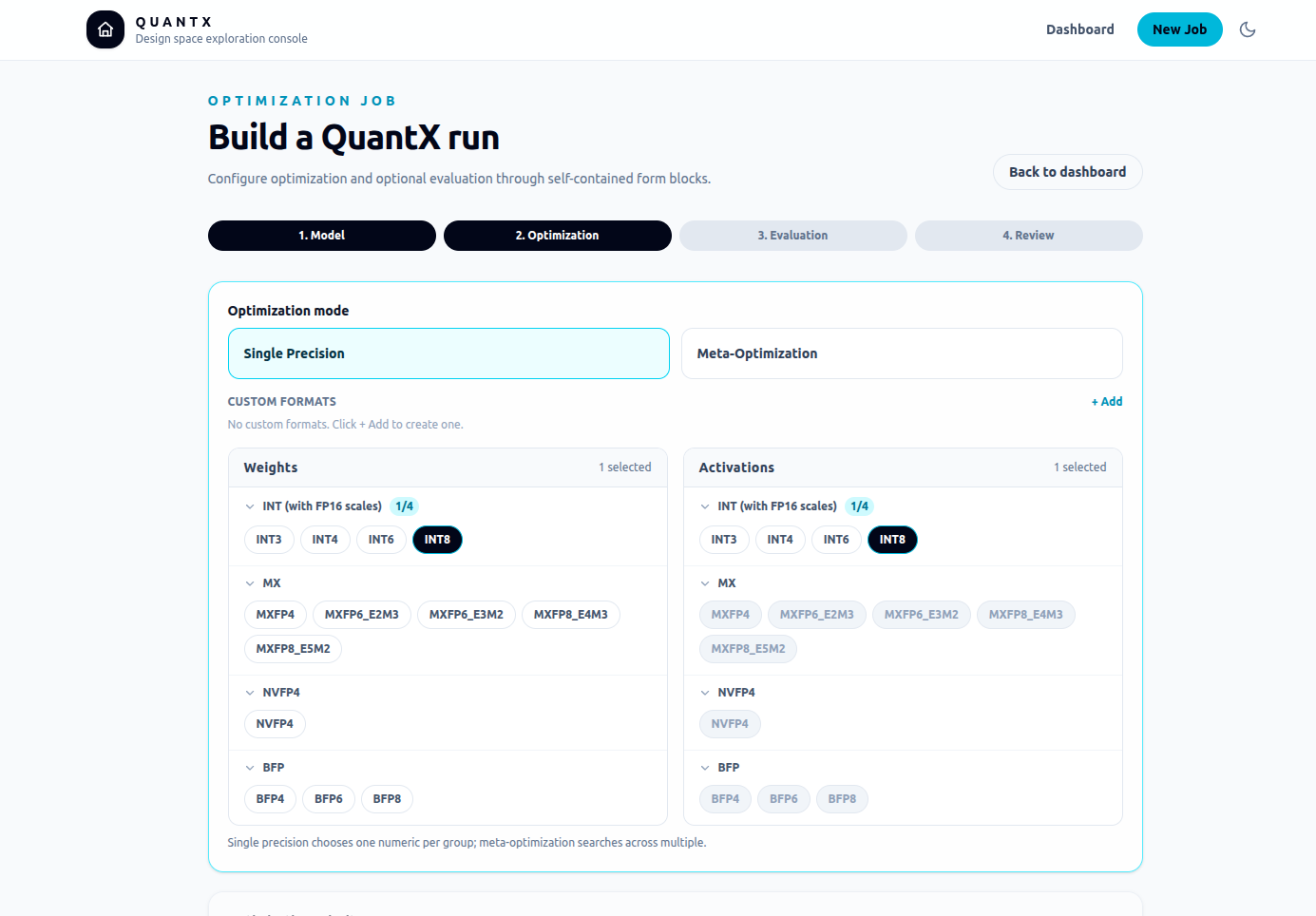
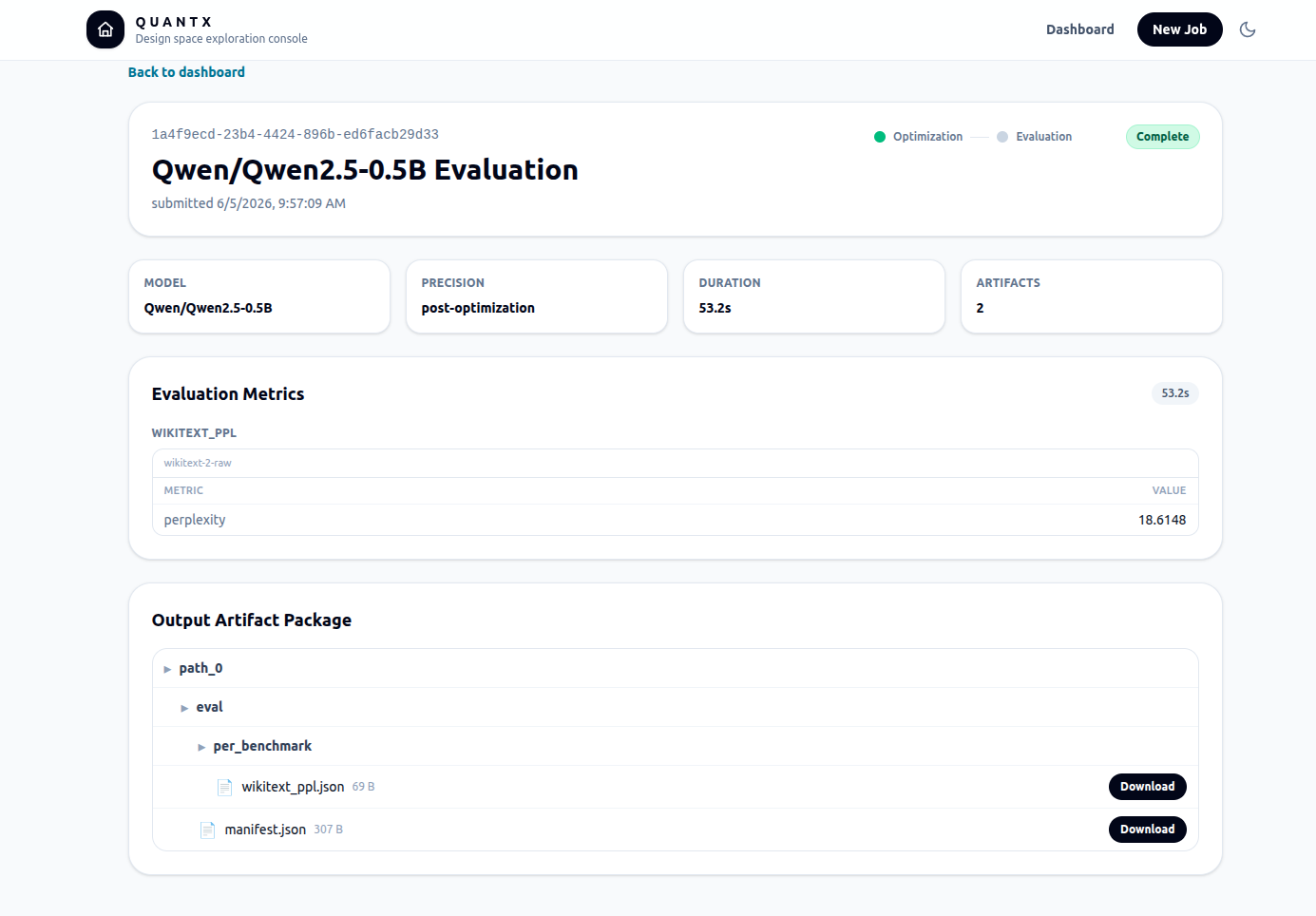
CASE STUDY
QuantX on Tenstorrent Hardware
QuantX-generated quantization settings deployed on Tenstorrent N300 silicon — measured against TT default published model settings across accuracy, storage, and throughput.
** Results using the TT inference test (prefill 512 tokens, generation 511 tokens) published online using an N300 in a single user setting. TT default — 'performance' published model settings v0.63.0 of tt-metal.
QuantX + Baltoro: The Complete AI Inference Stack
QuantX does not operate in isolation. When combined with Baltoro — 10xEngineers’ RISC-V-first AI compiler stack built on MLIR — QuantX-compressed models can be lowered all the way to optimised machine code for custom silicon.
- QuantX compresses the model using hardware-aware quantization matched to the target numeric format.
- Baltoro compiles the compressed model through Frontend → Compiler → Runtime, generating optimised inference code for RISC-V targets.
FAQ
Frequently Asked Questions
What is QuantX?
QuantX is a hardware-aware quantization design-space exploration platform developed by 10xEngineers. It is purpose-built for AI inference IP architects who need to evaluate custom numeric formats — including MXFP, BFP, INT8, and NVFP — against real LLMs and VLMs before committing to silicon tape-out. It also serves as a golden reference model for hardware validation and supports inference SDK deployment.
How is QuantX different from GPTQ, AutoAWQ, or bitsandbytes?
Tools like GPTQ, AutoAWQ, and bitsandbytes are designed for ML engineers deploying models on existing hardware with fixed numeric formats. QuantX is designed for an earlier and distinct decision: which numeric format to implement in new silicon. It natively supports custom and non-standard formats (BFP, NVFP) and provides hardware validation closure capabilities that deployment tools do not offer.
What numeric formats does QuantX support?
QuantX supports FP16 scale with INT elements, MXFP (Power-of-Two scale with FP elements per the OCP Microscaling standard), NVFP (FP8 scale + FP4 elements), and BFP (Block Floating Point with INT elements). Additional formats can be integrated through QuantX’s modular pipeline architecture.
What AI models does QuantX support?
QuantX supports Llama 2, Llama 3.1, and Llama 3.2; Qwen 2, Qwen 2.5, Qwen 3, and Qwen 3 VL; Llava-next 1.6 7B; SmolVLM and SmolVLM2; and legacy models including CLIP, OPT, and Stable Diffusion 1.5 / 3.5 / XL. 10xEngineers adds approximately one new model per month.
What is meta-optimization and how does it work?
Meta-optimization is QuantX’s automated multi-level bit allocation and algorithm selection engine. Given user constraints on model weight storage and peak inference memory, it allocates bit widths first at the transformer block level using importance scores, then refines at the per-tensor level within attention mechanisms — simultaneously selecting which quantization algorithms to activate based on the target numeric format.
Can QuantX serve as a golden reference model for hardware validation?
Yes. QuantX’s software-simulated quantization model is parameterised to match a specific hardware numeric format and datapath behaviour, and serves as the reference against which RTL simulations and physical silicon measurements are compared. 10xEngineers provides full-stack support for this workflow.
Does 10xEngineers build inference SDKs?
Yes. Beyond the QuantX platform, 10xEngineers offers two deployment services: integration of QuantX-compressed models into an existing inference SDK, and full inference SDK development from scratch tailored to the target hardware — drawing on full-stack expertise across ML compilers, runtime systems, and hardware-software co-design.
Talk to the QuantX Team
If you are architecting custom AI inference silicon and want to validate your numeric format decisions before tape-out — or if you need a golden reference model, a hardware validation partner, or an inference SDK — let’s talk.
- contact@10xengineers.ai
- San Diego, CA, USA